Значение числа 3
 Число 3 входит в резонанс с энергиями оптимизма и радости, вдохновения и креативности, речи и коммуникации, хорошего вкуса, воображения и интеллекта, общительности и общества, дружелюбия, доброты и сострадания.
Число 3 входит в резонанс с энергиями оптимизма и радости, вдохновения и креативности, речи и коммуникации, хорошего вкуса, воображения и интеллекта, общительности и общества, дружелюбия, доброты и сострадания.
Мистическое значение числа 3
Люди, в чьем жизненном наборе присутствует число 3 довольно часто проявляют экстрасенсорные способности, они часто увлекаются эзотерикой и оккультными науками. Между прочим, число 3 награждает своих обладателей и способностью казаться моложе своих лет, тем более, что они действительно довольно долго остаются молодыми в душе совершенно независимо от своего возраста.
Это и не случайно, ведь по своей сути данное число соединяет прошлое, настоящее и будущее. В китайской нумерологии число 3 считается числом человека, поскольку оно олицетворяет единство тела, духа и разума, а согласно Книге обрядов, человек является посредником между Землей и Небесами, что тоже представляет в совокупности число 3.
Вообще, древнекитайские нумерологии считают тройку одним из самых счастливых чисел жизненного набора. А древние Майя полагали ее, как священное число женщины.
Позитивные черты числа 3
Число 3 имеет непосредственное отношение к искусству, юмору, энергии, росту, увеличению, спонтанности, либеральным взглядам, поддержке, помощи, талантам и навыкам, культуре, остроумию, склонности к забавам и удовольствиям, поиску свободы, приключениям, изобилию, блеску, свободной форме, храбрости, неконфронтационности, чувству ритма, страсти, удивлению, чувствительности, самовыражению, любезности, энтузиазму.
Люди являющиеся носителями числа 3 являются прекрасными коммуникаторами, они очень артистичны, вдохновляющее оптимистичны и веселы. Список положительных качеств, которыми может наделить вас число 3 можно продолжать и продолжать практически бесконечно.
Отрицательные черты числа 3
Однако у него есть и свои отрицательные характеристики. Довольно часто людям, нумерологическим значением чьего имени или даты рождения оказывается число 3, бывает трудно сосредоточиться на каком-то конкретном деле, у них зачастую случаются довольно резкие перепады настроения, они могут страдать значительными фобиями или даже маниями.
В жизни носителей числа 3 могут подстерегать резкие взлеты и падения, она редко оказывается стабильной. Кром того, такие люди не всегда обладают достаточной стойкостью в достижении своей цели.
AstroMeridian.ru
P-значение
P-значение (англ. P-value) — величина, используемая при тестировании статистических гипотез. Фактически это вероятность ошибки при отклонении нулевой гипотезы (ошибки первого рода). Проверка гипотез с помощью P-значения является альтернативой классической процедуре проверки через критическое значение распределения.
Обычно P-значение равно вероятности того, что случайная величина с данным распределением (распределением тестовой статистики при нулевой гипотезе) примет значение, не меньшее, чем фактическое значение тестовой статистики.
Особенностью P-значений является их неустойчивость на эквивалентных выборках, что может стать препятствием для воспроизводимости результатов эксперимента[1][2][3]. Альтернативы использованию P-значений включают такие методы, как оценочная статистикаruen и фактор Байесаruen[4][5][6].
Формальное определение и процедура тестирования
Пусть T ( X ) {\displaystyle T(X)} — статистика, используемая при тестировании некоторой нулевой гипотезы H 0 {\displaystyle H_{0}} . Предполагается, что если нулевая гипотеза справедлива, то распределение этой статистики известно. Обозначим функцию распределения F ( t ) = P ( T t ) {\displaystyle F(t)=P(T
При проверке левосторонней альтернативы,
P 0 ( t ) = P ( T t ) = F ( t ) {\displaystyle P_{0}(t)=P(T
Если p(t) меньше заданного уровня значимости, то нулевая гипотеза отвергается в пользу альтернативной. В противном случае она не отвергается.
Преимуществом данного подхода является то, что видно при каком уровне значимости нулевая гипотеза будет отвергнута, а при каких принята, то есть виден уровень надежности статистических выводов, точнее вероятность ошибки при отвержении нулевой гипотезы. При любом уровне значимости больше p {\displaystyle p} нулевая гипотеза отвергается, а при меньших значениях — нет.
Критика
Использование p-значений для проверки нулевых гипотез в работах по медицине подвергается критике со стороны многих специалистов. Отмечается, что их использование нередко приводят к ошибкам первого рода (false positive). В частности, журнал Basic and Applied Social Psychology (BASP) в 2015 году вовсе запретил публикацию статей, в которых используются p-значения. Редакторы журнала объяснили это тем, что сделать исследование, в котором получено p < 0,05 не очень сложно, и такие низкие значения p слишком часто становятся оправданием для низкопробных исследований[7].
ru.wikipedia.org
В f-тесте используются следующие статистические гипотезы:
H0: β1= β2=... =βk= 0;
H1 : по крайней мере один из коэффициентов регрессии β1, β2, ... , βk 0.
Выполнить F-тест проще всего, отыскав в результатах работы компьютерной программы подходящее р-значение и интерпретировав результирующий уровень значимости. Если р-значение больше, чем 0,05, то полученный результат не является значимым. Если же это р-значение меньше, чем 0,05, то полученный результат является значимым. Если р< 0,01, тогда полученный результат является высоко значимым, и т.д.
Еще один способ выполнения F-теста заключается в сравнении значения R2(процент вариации У, который объясняется Х- переменными) со значениями из таблицы критических значений R2для подходящего уровня тестирования (например, 5%). Если значение R2оказывается достаточно большим, тогда регрессия считается значимой, т.е. удалось объяснить больше, чем просто случайную величину вариации У. Эта таблица индексирована по п(количество наблюдений) и k(количество Х- переменных).
Традиционный способ выполнения F-теста интерпретировать несколько сложнее, но он всегда дает тот же результат, что и таблица критических значений R2. КлассическийF-тест, как правило, выполняется путем вычисления Fстатистики и сравнения ее с критическим значением из F-таблицы для соответствующего уровня тестирования. При этом используются два разных числа степеней свободы: число степеней свободы k1(количество Х- переменных, предназначенных для объяснения У или количество параметров в уравнении регрессии минус единица, т.е.k1= m– 1) и число степеней свободы k2= n– m (где.n– количество наблюдений в выборке, а m – количество параметров в уравнении регрессии).
В то же время Fстатистика является излишним усложнением, поскольку значение R2можно проверить непосредственно. Более того, R2имеет более непосредственную интерпретацию, чем Fстатистика, поскольку R2говорит о той части вариации У, которая учитывается (или объясняется) Х- переменными, тогда как Fне имеет столь простой и непосредственной интерпретации в терминах исходных данных. Какой бы подход – Fили R2– вы ни использовали, ответ (о значимости или не значимости) всегда будет одним и тем же на любом уровне тестирования.
Почему же по традиции используется более сложная Fстатистика, в то время как вместо нее можно было бы обратиться к тесту R2, допускающему более удобную и непосредственную интерпретацию? Возможно, все объясняется именно сложившейся традицией, а возможно, и тем, что уже давно и с успехом на практике применяются именно F-таблицы. Использование осмысленного числа (такого как R2) позволяет глубже понять исследуемую ситуацию и выглядит предпочтительнее, особенно когда речь идет о сфере бизнеса.
Результат F-теста (решение принимается на основе р-значения)
Если р-значение больше, чем 0,05, значит, соответствующая модель не является значимой (вы принимаете нулевую гипотезу о том, что Х- переменные не помогают прогнозировать Y). Если р-значение оказывается меньше, чем 0,05, значит, соответствующая модель является значимой (вы отвергаете нулевую гипотезу и принимаете альтернативную гипотезу о том, что Х- переменные помогают прогнозировать Y).
Результат F-теста (решение принимается на основе R2)
Если значение R2меньше, чем критическое значение в таблице R2, значит, соответствующая модель не является значимой.. Если значение R2больше, чем критическое значение в таблице R2, значит, соответствующая модель является значимой. Этот ответ в любом случае будет таким же, как результат, полученный с помощью р-значения.
Результат F-теста (решение принимается на основе критерия F)
Если значение F оказывается меньше, чем критическое значение в F-таблице, значит, соответствующая модель не является значимой. Если значение Fоказывается больше, чем критическое значение в F-таблице,- соответствующая модель является значимой. Этот ответ в любом случае будет таким же, как результат, полученный с помощью р-значения или R2.
Помните, что статистический смысл термина «значимый» несколько отличается от его обыденного смысла. Когда вы находите значимую модель регрессии, то знаете, что взаимосвязь между Х- переменными и У оказывается сильнее, чем обычно можно было бы ожидать от чистой случайности. Другими словами, в этой ситуации можно говорить о наличии определенной взаимосвязи. Эта взаимосвязь может быть сильной или полезной в том или ином практическом смысле (а может, и не быть таковой) – эти вопросы требуют специального рассмотрения, – но она достаточно сильна, чтобы не выглядеть как чистая случайность.
Если вернуться к нашему примеру с тарифами на размещение рекламы в журналах, то соответствующее уравнение прогнозирования действительно объясняет значимую долю отклонения в тарифах, на что указывает в результатах работы компьютерной программы р-значение 0,000000 справа от значения F, равного 62,843. В табл. 5 содержится часть результатов работы компьютерной программы, приведенных в табл. 4.
Таблица 5. Результат множественной регрессионного анализа тарифов на размещение рекламы в журналах (вычисления сделаны в Excel)
|
ВЫВОД ИТОГОВ |
|||||
|
Регрессионная статистика |
|||||
|
Множествен. R |
0,887 |
||||
|
R-квадрат |
0,787 |
||||
|
Нормированный R-квадрат |
0,775 |
||||
|
Стандартная ошибка |
21577,870 |
р-значение |
|||
|
|
55 |
||||
|
Дисперсионный анализ |
|||||
|
df |
SS |
MS |
F |
Значимость F |
|
|
Регрессия |
3 |
87780733202 |
29260044401 |
62,843 |
0,000000 |
|
Остаток |
51 |
23745829151 |
465604493 |
||
|
Итого |
54 |
111525962353 |
|||
 Наблюдения
НаблюденияЭто говорит о том, что действительно обнаруживается устойчивая зависимость тарифов от этих факторов (или по крайней мере от одного из этих факторов), т.е. тарифы не являются чисто случайными величинами. Вам по-прежнему неизвестно, какие именно из этих Х- переменных реально участвуют в прогнозировании Y, но вам доподлинно известно, что есть по крайней мере одна такая переменная.
Чтобы выяснить с помощью R2, действительно ли уравнение регрессии является значимым, отметим, что коэффициент детерминации R2= 0,787, или 78,7%. Таблица R2для тестирования на уровне 5% в случае п=55 журналов и k=3переменных (табл. 6) дает критическое значение 0,141, или 14,1%. Для того чтобы уравнение было значимым на привычном уровне 5%, X- переменные должны объяснять лишь 14,1% вариации тарифов (Y). Поскольку они объясняют больше, регрессию следует признать значимой.
Таблица 6. Таблица R2: критические значения для уровня 5% (значимо)
|
Количество наблюдений (n) |
Количество Х-переменных (k) |
|||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
|
3 |
0,994 |
|||||||||
|
4 |
0,902 |
0,997 |
||||||||
|
5 |
0,771 |
0,950 |
0,998 |
|||||||
|
6 |
0,658 |
0,864 |
0,966 |
0,999 |
||||||
|
7 |
0,569 |
0,776 |
0,903 |
0,975 |
0,999 |
|||||
|
8 |
0,499 |
0,698 |
0,832 |
0,924 |
0,980 |
0,999 |
||||
|
9 |
0,444 |
0,632 |
0,764 |
0,865 |
0,938 |
0,983 |
0,999 |
|||
|
10 |
0,399 |
0,575 |
0,704 |
0,806 |
0,887 |
0,947 |
0,985 |
0,999 |
||
|
11 |
0,362 |
0,527 |
0,651 |
0,751 |
0,835 |
0,902 |
0,954 |
0,987 |
1,000 |
|
|
12 |
0,332 |
0,486 |
0,604 |
0,702 |
0,785 |
0,856 |
0,914 |
0,959 |
0,989 |
1,000 |
|
13 |
0,306 |
0,451 |
0,563 |
0,657 |
0,739 |
0,811 |
0,872 |
0,924 |
0,964 |
0,990 |
|
14 |
0,283 |
0,420 |
0,527 |
0,618 |
0,697 |
0,768 |
0,831 |
0,885 |
0,931 |
0,967 |
|
15 |
0,264 |
0,393 |
0,495 |
0,582 |
0,659 |
0,729 |
0,791 |
0,847 |
0,896 |
0,937 |
|
16 |
0,247 |
0,369 |
0,466 |
0,550 |
0,624 |
0,692 |
0,754 |
0,810 |
0,860 |
0,904 |
|
17 |
0,232 |
0,348 |
0,440 |
0,521 |
0,593 |
0,659 |
0,719 |
0,775 |
0,825 |
0,871 |
|
18 |
0,219 |
0,329 |
0,417 |
0,494 |
0,564 |
0,628 |
0,687 |
0,742 |
0,792 |
0,839 |
|
19 |
0,208 |
0,312 |
0,397 |
0,471 |
0,538 |
0,600 |
0,657 |
0,711 |
0,761 |
0,807 |
|
20 |
0,197 |
0,297 |
0,378 |
0,449 |
0,514 |
0,574 |
0,630 |
0,682 |
0,731 |
0,777 |
|
21 |
0,187 |
0,283 |
0,361 |
0,429 |
0,492 |
0,550 |
0,604 |
0,655 |
0,703 |
0,749 |
|
22 |
0,179 |
0,270 |
0,345 |
0,411 |
0,471 |
0,527 |
0,580 |
0,630 |
0,677 |
0,722 |
|
23 |
0,171 |
0,259 |
0,331 |
0,394 |
0,452 |
0,507 |
0,558 |
0,607 |
0,653 |
0,696 |
|
24 |
0,164 |
0,248 |
0,317 |
0,379 |
0,435 |
0,488 |
0,538 |
0,585 |
0,630 |
0,673 |
|
25 |
0,157 |
0,238 |
0,305 |
0,364 |
0,419 |
0,470 |
0,518 |
0,564 |
0,608 |
0,650 |
|
26 |
0,151 |
0,229 |
0,294 |
0,351 |
0,404 |
0,454 |
0,501 |
0,545 |
0,588 |
0,629 |
|
27 |
0,145 |
0,221 |
0,283 |
0,339 |
0,390 |
0,438 |
0,484 |
0,527 |
0,569 |
0,609 |
|
28 |
0,140 |
0,213 |
0,273 |
0,327 |
0,377 |
0,424 |
0,468 |
0,510 |
0,551 |
0,590 |
|
29 |
0,135 |
0,206 |
0,264 |
0,316 |
0,365 |
0,410 |
0,453 |
0,495 |
0,534 |
0,573 |
|
30 |
0,130 |
0,199 |
0,256 |
0,306 |
0,353 |
0,397 |
0,439 |
0,480 |
0,518 |
0,556 |
|
31 |
0,126 |
0,193 |
0,248 |
0,297 |
0,342 |
0,385 |
0,426 |
0,466 |
0,503 |
0,540 |
|
32 |
0,122 |
0,187 |
0,240 |
0,288 |
0,332 |
0,374 |
0,414 |
0,452 |
0,489 |
0,525 |
|
33 |
0,118 |
0,181 |
0,233 |
0,279 |
0,323 |
0,363 |
0,402 |
0,440 |
0,476 |
0,511 |
|
34 |
0,115 |
0,176 |
0,226 |
0,271 |
0,314 |
0,353 |
0,391 |
0,428 |
0,463 |
0,497 |
|
35 |
0,111 |
0,171 |
0,220 |
0,264 |
0,305 |
0,344 |
0,381 |
0,417 |
0,451 |
0,484 |
|
36 |
0,108 |
0,166 |
0,214 |
0,257 |
0,297 |
0,335 |
0,371 |
0,406 |
0,440 |
0,472 |
|
37 |
0,105 |
0,162 |
0,208 |
0,250 |
0,289 |
0,326 |
0,362 |
0,396 |
0,429 |
0,461 |
|
38 |
0,103 |
0,157 |
0,203 |
0,244 |
0,282 |
0,318 |
0,353 |
0,386 |
0,418 |
0,449 |
|
39 |
0,100 |
0,153 |
0,198 |
0,238 |
0,275 |
0,310 |
0,344 |
0,377 |
0,408 |
0,439 |
|
40 |
0,097 |
0,150 |
0,193 |
0,232 |
0,268 |
0,303 |
0,336 |
0,368 |
0,399 |
0,429 |
|
41 |
0,095 |
0,146 |
0,188 |
0,226 |
0,262 |
0,296 |
0,328 |
0,359 |
0,390 |
0,419 |
|
42 |
0,093 |
0,142 |
0,184 |
0,221 |
0,256 |
0,289 |
0,321 |
0,351 |
0,381 |
0,410 |
|
43 |
0,090 |
0,139 |
0,180 |
0,216 |
0,250 |
0,283 |
0,314 |
0,344 |
0,373 |
0,401 |
|
44 |
0,088 |
0,136 |
0,176 |
0,211 |
0,245 |
0,276 |
0,307 |
0,336 |
0,365 |
0,393 |
|
45 |
0,086 |
0,133 |
0,172 |
0,207 |
0,239 |
0,271 |
0,300 |
0,329 |
0,357 |
0,384 |
|
46 |
0,085 |
0,130 |
0,168 |
0,202 |
0,234 |
0,265 |
0,294 |
0,322 |
0,350 |
0,377 |
|
47 |
0,083 |
0,127 |
0,164 |
0,198 |
0,230 |
0,259 |
0,288 |
0,316 |
0,343 |
0,369 |
|
48 |
0,081 |
0,125 |
0,161 |
0,194 |
0,225 |
0,254 |
0,282 |
0,310 |
0,336 |
0,362 |
|
49 |
0,079 |
0,122 |
0,158 |
0,190 |
0,220 |
0,249 |
0,277 |
0,304 |
0,330 |
0,355 |
|
50 |
0,078 |
0,120 |
0,155 |
0,186 |
0,216 |
0,244 |
0,272 |
0,298 |
0,323 |
0,348 |
|
51 |
0,076 |
0,117 |
0,152 |
0,183 |
0,212 |
0,240 |
0,267 |
0,293 |
0,318 |
0,342 |
|
52 |
0,075 |
0,115 |
0,149 |
0,180 |
0,208 |
0,235 |
0,262 |
0,287 |
0,312 |
0,336 |
|
53 |
0,073 |
0,113 |
0,146 |
0,176 |
0,204 |
0,231 |
0,257 |
0,282 |
0,306 |
0,330 |
|
54 |
0,072 |
0,111 |
0,143 |
0,173 |
0,201 |
0,227 |
0,252 |
0,277 |
0,301 |
0,324 |
|
55 |
0,071 |
0,109 |
0,141 |
0,170 |
0,197 |
0,223 |
0,248 |
0,272 |
0,295 |
0,318 |
|
56 |
0,069 |
0,107 |
0,138 |
0,167 |
0,194 |
0,219 |
0,244 |
0,267 |
0,290 |
0,313 |
|
57 |
0,068 |
0,105 |
0,136 |
0,164 |
0,190 |
0,215 |
0,240 |
0,263 |
0,285 |
0,308 |
|
58 |
0,067 |
0,103 |
0,134 |
0,161 |
0,187 |
0,212 |
0,236 |
0,258 |
0,281 |
0,303 |
|
59 |
0,066 |
0,101 |
0,131 |
0,159 |
0,184 |
0,208 |
0,232 |
0,254 |
0,276 |
0,298 |
|
60 |
0,065 |
0,100 |
0,129 |
0,156 |
0,181 |
0,205 |
0,228 |
0,250 |
0,272 |
0,293 |
|
Множитель 1 |
3,84 |
5,99 |
7,82 |
9,49 |
11,07 |
12,59 |
14,07 |
15,51 |
16,92 |
18,31 |
|
Множитель 2 |
2,15 |
-0,27 |
-3,84 |
-7,94 |
-12,84 |
-18,24 |
-23,78 |
-30,10 |
-36,87 |
-43,87 |
Если у вас более 60 наблюдений, критические значения можно найти с помощью двух множителей, указанных внизу таблицы R2. Для этого необходимо воспользоваться следующей формулой:
StudFiles.ru
/ Пособие Экселя
Решение
-
Исследуемые данные введите в рабочую таблицу «MS Excel» по столбцам: в столбец А − заполняемость гостиниц в центре города, в столбец В − гостиниц, находящихся на расстоянии от 3 до 5 км и т. д. (диапазон А1:С6).
-
Выполните команду «Сервис» → «Анализ данных». В появившемся диалоговом окне Анализ данных в списке Инструменты анализа щелчком мыши выберите процедуру Однофакторный дисперсионный анализ. Нажмите кнопку ОК.
-
В появившемся диалоговом окне «Однофакторный дисперсионный анализ» в поле «Входной интервал» задайте А1:С1.Для этого наведите указатель мыши на ячейку А1 и протяните его к ячейке С6 при нажатой левой кнопке мыши.
-
В разделе «Группировка» переключатель установите в положение по столбцам.
-
Далее необходимо указать выходной диапазон. Для этого поставьте переключатель в положение Выходной интервал (наведите указатель мыши и щелкните левой кнопкой), затем щелкните указателем мыши в правом поле ввода Выходной интервал, и щелчком мыши на ячейке А8 укажите расположение выходного диапазона (рис. 1.17). Нажмите кнопку ОК.
Результаты анализа. В результате будет получена таблица, показанная на рис. 1.18.
|
Однофакторный дисперсионный анализ |
||||||
|
ИТОГИ |
||||||
|
Группы |
Счет |
Сумма |
Среднее |
Дисперсия |
||
|
Столбец 1 |
6 |
560 |
93,33333 |
13,4667 |
||
|
Столбец 2 |
6 |
516 |
86 |
14 |
||
|
Столбец 3 |
6 |
475 |
79,1667 |
32,9667 |
||
|
Дисперсионный анализ |
||||||
|
Источник вариации |
SS |
df |
MS |
F |
P-Значение |
F критическое |
|
Между группами |
602,3 |
2 |
301,166 |
14,95036 |
0,0002684 |
3,6823166 |
|
Внутри групп |
302,1 |
15 |
20,144 |
|||
|
Итого |
904,5 |
17 |
Рис. 1.18. Результат работы инструмента Однофакторный дисперсионный анализ
Интерпретация результатов.В таблице «Дисперсионный анализ» на пересечении строки Между группами и столбца Р-Значение находится величина 0,0002684. Величина Р-Значение < 0,05, следовательно, критерий Фишера значим и влияние фактора расстояния от центра города на эффективность заполнения гостиниц доказано статистически.
Упражнение
19. Определите, влияет ли фактор образования на уровень зарплаты в гостинице на основании следующих данных:
|
Образование |
Зарплата сотрудника |
|
высшее |
3200 3000 2600 2000 1900 1900 |
|
среднее спец |
2600 2000 2000 1900 1800 1800 |
|
среднее |
2000 2000 1900 1800 1700 1700 |
Корреляционный анализ
Важным разделом статистического анализа является корреляционный анализ, служащий для выявления взаимосвязей между выборками.
Коэффициент корреляции
Выявление взаимосвязей. Одна из наиболее распространенных задач статистического исследования состоит в изучении связи между некоторыми наблюдаемыми переменными. Знание взаимозависимостей отдельных признаков дает возможность решать одну из кардинальных задач любого научного исследования: возможность предвидеть, прогнозировать развитие ситуации при изменении конкретных характеристик объекта исследования. Например, основное содержание любой экономической политики, в конечном счете, может быть сведено к регулированию экономических переменных, осуществляемому на базе выявленной тем или иным образом информации об их взаимовлиянии. Поэтому, проблема изучения взаимосвязей показателей различного рода является одной из важнейших в статистическом анализе.
Обычно взаимосвязь между выборками носит не функциональный, а вероятностный (или стохастический) характер. В этом случае нет строгой, однозначной зависимости между величинами. При изучении стохастических зависимостей различают корреляцию и регрессию.
Регрессионный анализ (см. раздел «Регрессионный анализ») устанавливает формы зависимости между случайной величиной Y и значениями одной или нескольких переменных величин.
Корреляционный анализ состоит в определении степени связи между двумя случайными величинами X и Y. В качестве меры такой связи используется коэффициент корреляции. Коэффициент корреляции оценивается по выборке объема п связанных пар наблюдений (хi yi) из совместной генеральной совокупности X и Y. Существует несколько типов коэффициентов корреляции, применение которых зависит от предположений о совместном распределении величин X и Y.
Для оценки степени взаимосвязи наибольшее распространение получил коэффициент линейной корреляции (Пирсона), предполагающий нормальный закон распределения наблюдений.
Коэффициент корреляции (R, r) − параметр, характеризующий степень линейной взаимосвязи между двумя выборками. Коэффициент корреляции изменяется от -1 (строгая обратная линейная зависимость) до 1 (строгая прямая пропорциональная зависимость). При значении 0 линейной зависимости между двумя выборками нет. Здесь под прямой зависимостью понимают зависимость, при которой увеличение или уменьшение значения одного признака ведет, соответственно, к увеличению или уменьшению второго. Например, при увеличении температуры возрастает давление газа, а при уменьшении − снижается (при постоянном объеме). При обратной зависимости увеличение одного признака приводит к уменьшению второго и наоборот. Примером обратной корреляционной зависимости может служить связь между температурой воздуха на улице и количеством топлива, расходуемого на обогрев помещения.
Выборочный коэффициент линейной корреляции между двумя случайными величинами X и Y рассчитывается по формуле

Коэффициент корреляции является безразмерной величиной и его значение не зависит от единиц измерения случайных величин Xи Y.
На практике коэффициент корреляции принимает некоторые промежуточные значения между 1 и -1 (рис. 1.19). Для оценки степени взаимосвязи можно руководствоваться следующими эмпирическими правилами. Если коэффициент корреляции (r) по абсолютной величине (без учета знака) больше, чем 0,95, то принято считать, что между параметрами существует практически линейная зависимость, (прямая − при положительном r и обратная − при отрицательном r). Если коэффициент корреляции r лежит в диапазоне от 0,8 до 0,95, говорят о сильной степени линейной связи между параметрами. Если 0,6 < \r\ < 0,8, говорят о наличии линейной связи между параметрами. При \r\ < 0,4 обычно считают, что линейная взаимосвязь между параметрами выявить не удалось.
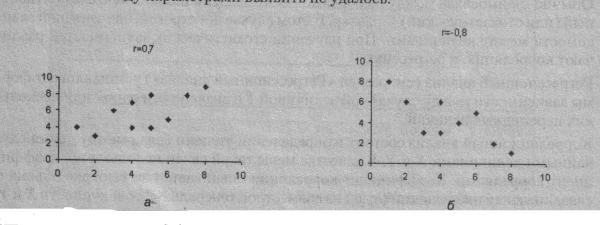
Рис. 1.19. Примеры прямой (r» 0,7, а) и обратной (r= -0,8, б) корреляционной зависимости
О В MS «MS Excel» для вычисления парных коэффициентов линейной корреляции используется специальная функция К0РРЕЛ. Параметрами функции являются К0РРЕЛ(масив1;массив2), где: массив1 — это диапазон ячеек первой случайной величины;
О массив2 − это второй интервал ячеек со значениями второй случайной величины.
Пример 1.13. Имеются результаты семимесячных наблюдений реализации путевок двух туристских маршрутов тура А и тура В.
|
Тур А |
Тур В |
|
120 |
20 |
|
121 |
15 |
|
105 |
18 |
|
92 |
16 |
|
113 |
19 |
|
90 |
16 |
|
80 |
15 |
Необходимо определить, имеется ли взаимосвязь между количеством продаж путевок обоих маршрутов.
Решение
Для выявления степени взаимосвязи, прежде всего, необходимо ввести данные в рабочую таблицу.
Откройте новую рабочую таблицу. Введите в ячейку А1 слова Тур А. Затем в ячейки А2:А8 − соответствующие значения числа продаж. В ячейки В1:В8 введите название и значения для тура В. Затем вычисляется значение коэффициента корреляции между выборками. Для этого табличный курсор установите в свободную ячейку (А9). На панели инструментов нажмите кнопку Вставка функции (fx). В появившемся диалоговом окне Мастер функций выберите категорию Статистические и функцию КОРРЕЛ, после чего нажмите кнопку ОК. Появившееся диалоговое окно КОРРЕЛ за серое поле мышью отодвиньте вправо на 1-2 см от данных (при нажатой левой клавише). Указателем мыши введите диапазон данных Тур А в поле Массив 1 (А2:А8). В поле Массив 2 введите диапазон данных Тур В (В2:В8). Нажмите кнопку ОК. В ячейке А9 появится значение коэффициента корреляции − 0,995493. Значение коэффициента корреляции больше чем 0,95. Значит, можно говорить о том, что в течение периода наблюдения имелась высокая степень прямой линейной взаимосвязи между количествами проданных путевок обоих маршрутов (r= 0,557292).
Корреляционная матрица
При большом числе наблюдений, когда коэффициенты корреляции необходимо последовательно вычислять из нескольких рядов числовых данных, для удобства получаемые коэффициенты сводят в таблицы, называемые корреляционными матрицами.
Корреляционная матрица − это квадратная (или прямоугольная) таблица, в которой на пересечении соответствующих строки и столбца находится коэффициент корреляции между соответствующими параметрами.
В MS «MS Excel» для вычисления корреляционных матриц используется процедура Корреляция. Процедура позволяет получить корреляционную матрицу, содержащую коэффициенты корреляции между различными параметрами.
Для реализации процедуры необходимо:
О выполнить команду Сервис → Анализ данных;
О в появившемся списке Инструменты анализа выбрать строку Корреляция и нажать кнопку ОК;
О в появившемся диалоговом окне указать Входной интервал, то есть ввести ссылку на ячейки, содержащие анализируемые данные. Для этого следует навести указатель мыши на левую верхнюю ячейку данных, нажать левую кнопку мыши и, не отпуская ее, протянуть указатель мыши к правой нижней ячейке, содержащей анализируемые данные, затем отпустить левую кнопку мыши. Входной интервал должен содержать не менее двух столбцов.
О в разделе Группировка переключатель установить в соответствии с введенными данными;
О указать выходной диапазон, то есть ввести ссылку на ячейки, в которые будут выведены результаты анализа. Для этого следует поставить флажок в левое поле Выходной интервал (навести указатель мыши и щелкнуть левой кнопкой), далее навести указатель мыши на правое поле ввода Выходной интервал и щелкнуть левой кнопкой мыши, затем указатель мыши навести на левую верхнюю ячейку выходного диапазона и щелкнуть левой кнопкой мыши. Размер выходного диапазона будет определен автоматически, и на экран будет выведено сообщение в случае возможного наложения выходного диапазона на исходные данные (рис. 1.20).
О нажать кнопку ОК.
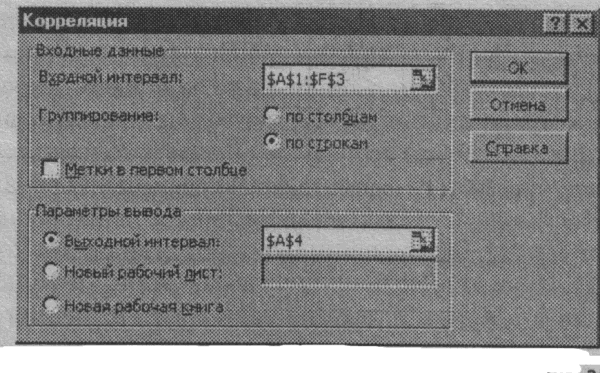
Рис. 1.20. Пример установки параметров корреляционного анализа
Результаты анализа. В выходной диапазон будет выведена корреляционная матрица, в которой на пересечении каждых строки и столбца находится коэффициент корреляции между соответствующими параметрами. Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждый столбец во входном диапазоне полностью коррелирует с самим собой.
Интерпретация результатов. Рассматривается отдельно каждый коэффициент корреляции между соответствующими параметрами. Его числовое значение оценивается по эмпирическим правилам, изложенным в разделе «Коэффициент корреляции». Отметим, что хотя в результате будет получена треугольная матрица, корреляционная матрица симметрична, и коэффициенты корреляции
rij=rji.
Пример 1.14. Имеются ежемесячные данные наблюдений за состоянием погоды и посещаемостью музеев и парков.
Число ясных днейКоличество посетителей музея Количество посетителей парка
|
8 |
495 |
132 |
|
14 |
503 |
348 |
|
20 |
380 |
643 |
|
25 |
305 |
865 |
|
20 |
348 |
743 |
|
15 |
465 |
541 |
Необходимо определить, существует ли взаимосвязь между состоянием погоды и посещаемостью музеев и парков.
Решение. Для выполнения корреляционного анализа введите в диапазон А1:С3исходные данные (рис. 1.21).
Затем в меню Сервис выберите пункт Анализ данных и далее укажите строку Корреляция. В появившемся диалоговом окне укажите Входной интервал В1:G3. Укажите, что данные рассматриваются по строкам.Укажите выходной диапазон. Для этого поставьте флажок в левое поле Выходной интервал и в правое поле ввода Выходной интервал введите А4 (рис. 1.20). Нажмите кнопку ОК.
|
A |
B |
C |
D |
E |
F |
G |
|
|
1 |
Ясные дни |
8 |
14 |
20 |
25 |
20 |
15 |
|
2 |
Посещаемость музея |
495 |
503 |
380 |
305 |
348 |
465 |
|
3 |
Посещаемость парка |
132 |
348 |
643 |
865 |
743 |
541 |
Рис. 1.21. Исходные данные из примера 1.14
|
Строка 1 |
Строка 2 |
Строка 3 |
|
|
Строка 1 |
1 |
||
|
Строка 2 |
-0,921 |
1 |
|
|
Строка 3 |
0,974 |
-0,919 |
1 |
Рис. 1.22. Результаты вычисления корреляционной матрицы из примера 1.14
Результаты анализа. В выходном диапазоне получаем корреляционную матрицу (рис. 1.22).
Интерпретация результатов. Из таблицы видно, что корреляция между состоянием погоды и посещаемостью музея равна -0,92, а между состоянием погоды и посещаемостью парка −0,97, между посещаемостью парка и музея − r=-0,92.
Таким образом, в результате анализа выявлены зависимости: сильная степень обратной линейной взаимосвязи между посещаемостью музея и количеством солнечных дней (r =-0,92) и практически линейная (очень сильная прямая) связь между посещаемостью парка и состоянием погоды (r = 0,97). Между посещаемостью музея и парка имеется сильная обратная взаимосвязь (r= -0,92).
Подразумевается, что в пустых клетках в правой верхней половине таблицы находятся те же коэффициенты корреляции, что и в нижней левой (симметрично расположенные относительно диагонали).
Упражнения
-
Определите, имеется ли взаимосвязь между рождаемостью и смертностью (количество на 1000 человек) в Санкт-Петербурге:
|
Годы |
Рождаемость |
Смертность |
|
1991 |
9,3 |
12,5 |
|
1992 |
7,4 |
13,5 |
|
1993 |
6,6 |
17,4 |
|
1994 |
7,1 |
17,2 |
|
1995 |
7,0 |
15,9 |
|
1996 |
6,6 |
14,2 |
21. Определите, имеется ли взаимосвязь между годовым уровнем инфляции (%), ставкой рефинансирования (%) и курсом доллара (руб./$), по следующим данным ежегодных наблюдений:
Уровень инфляцииСтавка рефинансированияКурс $
84 85 6,3
45 55 14
56 65 20
34 40 28
23 28 29
Регрессионный анализ
При исследовании взаимосвязей между выборками помимо корреляции различают также и регрессию. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или более независимых переменных. Соответственно, наряду с корреляционным анализом еще одним инструментом -изучения стохастических зависимостей является регрессионный анализ.
Регрессионный анализ устанавливает формы зависимости между случайной величиной Y (зависимой) и значениями одной или нескольких переменных величин (независимых), причем значения последних считаются точно заданными. Такая зависимость обычно определяется некоторой математической моделью (уравнением регрессии), содержащей несколько неизвестных параметров. В ходе регрессионного анализа на основании выборочных данных находят оценки этих параметров, определяются статистические ошибки оценок или границы доверитель интервалов и проверяется соответствие (адекватность) принятой математической модели экспериментальным данным.
В линейном регрессионном анализе связь между случайными величинами предполагается линейной. В самом простом случае в линейной регрессионной модели имеются две переменные Xи Y. И требуется по п парам наблюдений (X1,Y1), (Х2, Y2),…,(ХnYn) построить (подобрать) прямую линию, называемую линией регрессии, которая «наилучшим образом» приближает наблюдаемые значения. Yравнение этой линии Y= аХ + bявляется регрессионным уравнением. С помощью_ регрессионного уравнения можно предсказать ожидаемое значение зависимости личины Y0, соответствующее заданному значению независимой переменной Х0.
Таким образом, можно сказать, что линейный регрессионный анализ заключало в подборе графика и его уравнения для набора наблюдений. В регрессионном анализе все признаки (переменные), входящие в уравнение, должны иметь непрерывную, а не дискретную природу.
В случае, когда рассматривается зависимость между одной зависимой переменной
Y и несколькими независимыми ХиХ2,..., Хn, говорят о множественной линейной
регрессии. В этом случае регрессионное уравнение имеет вид
Y= а0+ a1X1+ а2Х2+... + апХn
где а1, а2, ..., аn− требующие определения коэффициенты при независимых переменных Х1, Х2, ...,Хп а0− константа.Мерой эффективности регрессионной модели является коэффициент детерминации R2(R-квадрат). Коэффициент детерминации (R-квадрат) определяет, с какой степенью точности полученное регрессионное уравнение описывает (аппроксимирует) исходные данные.
Исследуется также значимость регрессионной модели с помощью F-критерия (Фишера). Если величина F-критерия значима (р < 0,05), то регрессионная модель является значимой.
Достоверность отличия коэффициентов a0, а1, а2, аnот нуля проверяется с помощью критерия Стьюдента. В случаях, когда р > 0,05, коэффициент может считаться нулевым, а это означает, что влияние соответствующей независимой переменной на зависимую переменную недостоверно, и эта независимая переменная может быть исключена из уравнения.
В MS «MS Excel» экспериментальные данные аппроксимируются линейным уравнением до 16 порядка: У= а0 + a1X1+ а2Х2+ ... + аnХn,
где Y− зависимая переменная, X1, ...,Хn − независимые переменные, а0, а1, ..., аn − искомые коэффициенты регрессии.
Для получения коэффициентов регрессии используется процедура Регрессия из пакета анализа. Кроме того, могут быть использованы функция Л ИНЕЙН для получения параметров регрессионного уравнения и функция ТЕНДЕНЦИЯ для получения предсказанных значений Y в требуемых точках (см. раздел «Несколько независимых переменных» главы 3).
Для реализации процедуры Регрессия необходимо:
О выполнить команду «Сервис» → «Анализ данных»;
О в появившемся диалоговом окне Анализ данных в списке Инструменты анализа выбрать строку Регрессия, указав курсором мыши и щелкнув левой кнопкой мыши. Затем нажать кнопку 0К;
О в появившемся диалоговом окне задать Входной интервал Y, то есть ввести ссылку на диапазон анализируемых зависимых данных, содержащий один столбец данных. Для этого следует навести указатель мыши на верхнюю ячейку столбца зависимых данных, нажать левую кнопку мыши и, не отпуская ее, протянуть указатель мыши к нижней ячейке, содержащей анализируемые данные, затем отпустить левую кнопку мыши;
О указать Входной интервал X, то есть ввести ссылку на диапазон независимых данных, содержащий до 16 столбцов анализируемых данных. Для этого следует навести указатель мыши на поле ввода Входной интервал X и щелкнуть левой кнопкой мыши, затем навести указатель мыши на верхнюю левую ячейку диапазона независимых данных, нажать левую кнопку мыши и, не отпуская ее, протянуть указатель мыши к нижней правой ячейке, содержащей анализируемые данные, затем отпустить левую кнопку мыши;
StudFiles.ru
Задание 3. Проверить значимость коэффициента корреляции при уровне значимости 0,05
Для проверки значимости выборочного коэффициента корреляции надо проверить нулевую гипотезу
H0: 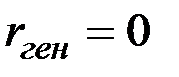 (
( 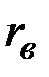 не значим).
не значим).
H1: 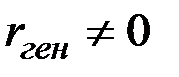 ( значим).
( значим).
Критическая область –_______________________ .
Гипотеза H0 проверяется с помощью критерия 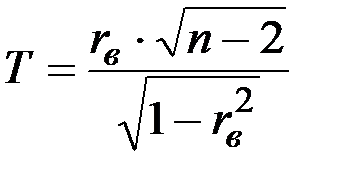 .
.
Подставляя в эту формулу значение и  , найти
, найти
 .
.
Критическую точку 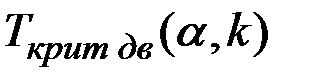 , где
, где 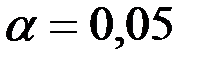 ,
, 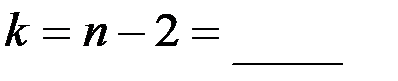 , найти с помощью функции СТЬЮДРАСПОБР следующим образом:
, найти с помощью функции СТЬЮДРАСПОБР следующим образом:
1. Установить табличный курсор в свободную ячейку, например в А1. Нажать на панели инструментов кнопку Вставка функции (fx).
2. В появившемся диалоговом окне Мастер функций выбрать категорию Статистические и функцию СТЬЮДРАСПОБР. Нажать кнопку ОК.
3. Появляется диалоговое окно СТЬЮДРАСПОБР. В рабочее поле Вероятность ввести с клавиатуры значение уровня значимости 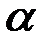 (в примере – 0,05), в рабочее поле Степени свободы ввести число степеней свободы
(в примере – 0,05), в рабочее поле Степени свободы ввести число степеней свободы 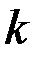 (в примере – 10). Нажать кнопку ОК.
(в примере – 10). Нажать кнопку ОК.
4. В ячейке А1 появится значение 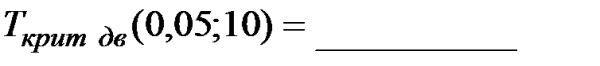 .
.
Далее сравнить  и
и  и сделать вывод:
и сделать вывод:
__________________________________________________________________
__________________________________________________________
Задание 4. Найти коэффициент детерминации R2 и сформулировать его экономический смысл.
Найти коэффициент детерминации  .
.
Учитывая, что 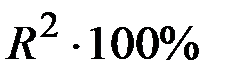 показывает, на сколько процентов в среднем вариация объясняемой переменной Y обусловлена вариацией объясняющей переменной X, устно сформулировать экономический смысл коэффициента детерминации.
показывает, на сколько процентов в среднем вариация объясняемой переменной Y обусловлена вариацией объясняющей переменной X, устно сформулировать экономический смысл коэффициента детерминации.
studopedia.ru
 Что значит camera 2
Что значит camera 2 Бабочка значение
Бабочка значение Барыга значение слова википедия
Барыга значение слова википедия 16 16 Значение времени
16 16 Значение времени Что значит ip
Что значит ip Что значит lol в переписке на английском
Что значит lol в переписке на английском 23 23 Значение
23 23 Значение Славянские имена мальчиков и их значение
Славянские имена мальчиков и их значение 666 Что значит
666 Что значит Эскалировать значение слова
Эскалировать значение слова Что значит авторизация
Что значит авторизация Снятся пауки что это значит
Снятся пауки что это значит