/ СПСС 10
Задание № 10 Корреляционный анализ
Понятие корреляции
Корреляция или коэффициент корреляции – это статистический показательвероятностнойсвязи между двумя переменными, измеренными по количественным шкалам. В отличие от функциональной связи, при которой каждому значению одной переменной соответствуетстрого определенноезначение другой переменной,вероятностная связьхарактеризуется тем, что каждому значению одной переменной соответствуетмножество значенийдругой переменной, Примером вероятностной связи является связь между ростом и весом людей. Ясно, что один и тот же рост может быть у людей разного веса и наоборот.
Корреляция представляет собой величину, заключенную в пределах от -1 до + 1, и обозначается буквой r. Причем, если значение находится ближе к 1, то это означает наличие сильной связи, а если ближе к 0, то слабой. Значение корреляции менее 0,2 рассматривается как слабая корреляция, свыше 0,5 – высокая. Если коэффициент корреляции отрицательный, это означает наличие обратной связи: чем выше значение одной переменной, тем ниже значение другой.
В зависимости от принимаемых значений коэффициента rможно выделить различные виды корреляции:
Строгая положительная корреляцияопределяется значениемr=1. Термин «строгая» означает, что значение одной переменной однозначно определяются значениями другой переменной, а термин «положительная» - что с возрастанием значений одной переменной значения другой переменной также возрастают.
Строгая корреляция является математической абстракцией и практически не встречается в реальных исследованиях.
Положительная корреляция соответствует значениям 0
Отсутствие корреляцииопределяется значениемr=0. Нулевой коэффициент корреляции говорит о том, что значения переменных никак не связаны между собой.
Отсутствие корреляции Ho: 0rxy=0формулируется как отражениенулевой гипотезы в корреляционном анализе.
Отрицательная корреляция: -1
Строгая отрицательная корреляцияопределяется значениемr= -1. Она также, как и строгая положительная корреляция, является абстракцией и не находит выражение в практических исследованиях.
Таблица 1
Виды корреляции и их определения
|
Виды |
Определения |
|
Строгая положительная корреляция |
r=1 |
|
Положительная корреляция |
0< r |
|
Отсутствие корреляции |
r=0. |
|
Отрицательная корреляция |
-1 |
|
Строгая отрицательная корреляция |
r= -1 |
Метод вычисления коэффициента корреляции зависит от вида шкалы, по которой измерены значения переменной.
Коэффициент корреляции rПирсонаявляется основным и может использоваться для переменных с номинальной и частично упорядоченными, интервальными шкалами, распределение значений по которым соответствует нормальному (корреляция моментов произведения). Коэффициент корреляции Пирсона дает достаточно точные результаты и в случаях анормальных распределений.
Для распределений, не являющихся нормальными, предпочтительнее пользоваться коэффициентами ранговой корреляции Спирмена и Кендалла. Ранговыми они являются потому, что программа предварительно ранжирует коррелируемые переменные.
Корреляцию rСпирмена программаSPSSвычисляет следующим образом: сначала переменные переводятся в ранги, а затем к рангам применяется формулаrПирсона.
В основе корреляции, предложенной М. Кендаллом, лежит идея о том, что о направлении связи можно судить, попарно сравнивая между собой испытуемых. Если у пары испытываемых изменение по Х совпадают по направлению с изменением по Yсовпадает, то это свидетельствует о положительной связи. Если не совпадает – то об отрицательной связи. Данный коэффициент применяется преимущественно психологами, работающими с малыми выборками. Так как социологи работают с большими массивами данных, то перебор пар, выявление разности относительных частот и инверсий всех пар испытуемых в выборке затруднителен. Наиболее распространенным является коэф. Пирсона.
Поскольку коэффициент корреляции rПирсона является основным и может использоваться (с некоторой погрешностью в зависимости от типа шкалы и уровня анормальности в распределении) для всех переменных, измеренных по количественным шкалам, рассмотрим примеры его использования и сравним полученные результаты с результатами измерений по другим коэффициентам корреляции.
Формула вычисления коэффициента r- Пирсона:
rxy= ∑ (Xi-Xср)∙(Yi-Yср) / (N-1)∙σx∙σy∙
Где: Xi, Yi- Значения двух переменных;
Xср, Yср- средние значения двух переменных;
σx,σy– стандартные отклонения,
N- количество наблюдений.
Парные корреляции
Например, мы хотели бы выяснить, как соотносятся ответы между различными видами традиционных ценностей в представлениях студентов об идеальном месте работы (переменные: а9.1, а9.3, а9.5, а9.7), а затем о соотношении либеральных ценностях (а9.2, а9.4. а9.6, а9.8) . Данные переменные измерены по 5 – членным упорядоченным шкалам.
Используем процедуру: «Анализ», «Корреляции»,«Парные». По умолчанию коэф. Пирсона установлен в диалоговом окне. Используем коэф. Пирсона
.В окно отбора переносятся тестируемые переменные: а9.1, а9.3, а9.5, а9.7
Путем нажатия ОК получаем расчет:
Корреляции
|
а9.1.т. Насколько важно иметь достаточно времени для семьи и личной жизни? |
а9.3.т. Насколько важно не бояться потерять свою работу? |
а9.5.т. Насколько важно иметь такого начальника, который будет советоваться с Вами, принимая то или иное решение ? |
а9.7.т. Насколько важно работать в слаженном коллективе, ощущать себя его частью? |
||
|
а9.1.т. Насколько важно иметь достаточно времени для семьи и личной жизни? |
Корреляция Пирсона |
1 |
,138(**) |
,040 |
,157(**) |
|
Знч.(2-сторон) |
,003 |
,389 |
,001 |
||
|
N |
458 |
452 |
458 |
451 |
|
|
а9.3.т. Насколько важно не бояться потерять свою работу? |
Корреляция Пирсона |
,138(**) |
1 |
,202(**) |
,188(**) |
|
Знч.(2-сторон) |
,003 |
,000 |
,000 |
||
|
N |
452 |
460 |
459 |
453 |
|
|
а9.5.т. Насколько важно иметь такого начальника, который будет советоваться с Вами, принимая то или иное решение ? |
Корреляция Пирсона |
,040 |
,202(**) |
1 |
,193(**) |
|
Знч.(2-сторон) |
,389 |
,000 |
,000 |
||
|
N |
458 |
459 |
465 |
458 |
|
|
а9.7.т. Насколько важно работать в слаженном коллективе, ощущать себя его частью? |
Корреляция Пирсона |
,157(**) |
,188(**) |
,193(**) |
1 |
|
Знч.(2-сторон) |
,001 |
,000 |
,000 |
||
|
N |
451 |
453 |
458 |
460 |
** Корреляция значима на уровне 0.01 (2-сторон.).
Таблица количественных значений построенной корреляционной матрицы
|
Признаки |
Количество |
|
Размер корреляционной матрицы |
4×4 |
|
Количество коэффициентов корреляции |
6 |
|
Количество значимых коэффициентов корреляции (при Р |
5 |
|
В т.ч. с положительной связью |
5 |
|
В т.ч. с отрицательной связью |
0 |
Частные корреляции:
Для начала построим парную корреляцию между указанными двумя переменными:
|
Корреляции |
|||
|
с8. Ощущают близость с теми, кто живет рядом с вами, соседями |
с12. Ощущают близость со своей семьей |
||
|
с8. Ощущают близость с теми, кто живет рядом с вами, соседями |
Корреляция Пирсона |
1 |
,120** |
|
Знч.(2-сторон) |
,001 |
||
|
N |
718 |
698 |
|
|
с12. Ощущают близость со своей семьей |
Корреляция Пирсона |
,120** |
1 |
|
Знч.(2-сторон) |
,001 |
||
|
N |
698 |
748 |
|
|
**. Корреляция значима на уровне 0.01 (2-сторон.). |
|||
Затем используем процедуру построения частной корреляции: «Анализ», «Корреляции»,«Частные».
Предположим, что ценность «Важно самостоятельно определять и изменять порядок своей работы» во взаимосвязи с указанными переменными окажется тем решающим фактором, под влияние которого ранее выявленная связь исчезнет, либо окажется малозначимой.
|
Корреляции |
||||
|
Исключенные переменные |
с8. Ощущают близость с теми, кто живет рядом с вами, соседями |
с12. Ощущают близость со своей семьей |
||
|
с16. Ощущают близость с людьми, котрые имеют тот же достаток, что и вы |
с8. Ощущают близость с теми, кто живет рядом с вами, соседями |
Корреляция |
1,000 |
,102 |
|
Значимость (2-сторон.) |
. |
,012 |
||
|
ст.св. |
0 |
599 |
||
|
с12. Ощущают близость со своей семьей |
Корреляция |
,102 |
1,000 |
|
|
Значимость (2-сторон.) |
,012 |
. |
||
|
ст.св. |
599 |
0 |
||
Как видно из таблицы под влиянием контрольной переменной связь несколько снизилась: с 0, 120 до 0, 102. Однако, это незначительно снижение не позволяет утверждать, что ране выявленная связь является отражением ложной корреляции, т.к. она остается достаточно высокой и позволяет с нулевой погрешностью опровергать нулевую гипотезу.
StudFiles.ru
/ эконометрика
|
Вопрос |
Ответ |
Верно |
|
1. Что является предметом изучения эконометрики? |
факторы, формирующие развитие экономических явлений и процессов |
да |
|
103. Как рассчитывается коэффициент детерминации? |
ESS / TSS |
нет |
|
110. Каким образом при решении регрессионной задачи в пакете Excel обнаруживаются статистические выбросы? |
по величинам Р-значений |
нет |
|
111. В каких случаях не обязательно удаление статистических выбросов? |
статистические выбросы необходимо исключать из модели всегда |
нет |
|
126. Что означает отрицательный коэффициент при бинарной переменной? |
наличие статистических выбросов |
нет |
|
19. Регрессия у на х - это |
сумма дисперсий у и х |
нет |
|
20. Какой метод позволяет определить оценки параметров регрессии? |
метод факторного анализа |
нет |
|
25. Для чего применяется МНК? |
для расчета Мат. ожидания, Нелинейности и Коэффициента вариации |
нет |
|
4. Для решения эконометрических задач необходимо |
наличие специализированных программных средств |
нет |
|
41. Уравнение регрессии записывается на основании |
величины коэффициента корреляции |
нет |
|
46. В уравнении регрессии параметры обычно обозначаются как |
R и R-квадрат |
нет |
|
47. В уравнение регрессии входят |
зависимая переменная, независимые переменные и коэффициенты при них |
да |
|
5. Что такое математическая модель экономического объекта? |
совокупность числовых характеристик, характеризующих экономический объект |
нет |
|
51. В уравнении y = a + bx коэффициенты а и b - это: |
доверительные интервалы параметров регрессии |
нет |
|
56. В уравнении y = a + bx величина коэффициента а отражает |
значение у при единичном увеличении х |
нет |
|
61. Чему будет равен Y в множественной линейной регрессии, если Y-пересечение = 10, b1 = 1, b2 = 2, х1 = 3, x2 = 4? |
10 |
нет |
|
7. Что может быть выполнено с помощью эконометрической модели? |
приведение размерности различных случайных величин к единой величине |
нет |
|
71. Что означает не значимость коэффициента регрессии? |
что соответствующая ему независимая переменная не влияет на зависимую |
да |
|
73. Что означает статистическая незначимость параметра (коэффициента) регрессии? |
недостаточность количества исходных наблюдений |
нет |
|
75. Какая величина «Р-значения» подтверждает влияние х на у? |
Р-значение для него по модулю больше либо равно 0,7 |
нет |
|
88. Величина «Значимость F» показывает |
вероятность незначимости соответствующего коэффициента регрессии |
нет |
|
9. В эконометрических задачах математическая модель |
это уравнение регрессии или система уравнений регрессии |
да |
|
90. Нулевая гипотеза для коэфициента детерминации отвергается при |
Р-значении, меньшем или равном 5% |
нет |
|
91. Что означает незначимость коэффициента детерминации? |
что рассчитанный коэффициент детерминации не достоверен |
да |
|
92. В каком случае коэффициент детерминации может быть не достоверен? |
в случае, если он отрицателен |
нет |
|
Вопрос |
Ответ |
Верно |
|
107. Что такое статистический выброс? |
наблюдение, для которого совпадают реальное и расчетное значения y |
нет |
|
108. Что такое статистический выброс? |
процесс отбрасывания незначимых переменных модели |
нет |
|
11. Что означает наличие обратной связи между переменными х и у? |
что графики переменных х и у не являются прямыми линиями |
нет |
|
111. В каких случаях не обязательно удаление статистических выбросов? |
в случае сильной связи в регрессионной модели |
да |
|
116. Что такое бинарная переменная? |
переменная, принимающая значения "0" или "1" при наличии или отсутствии признака |
да |
|
117. Фиктивная переменная - это |
переменная, не отражаемая в уравнении регрессии |
нет |
|
118. Бинарная переменная является |
показателем качества регрессионной модели |
нет |
|
121. Можно ли использовать бинарные переменные в множественной регрессии? |
да, если наблюдений не менее 2 |
нет |
|
17. Оценка вида связи между переменными возможна |
с помощью балансового анализа |
нет |
|
27. В каком случае регрессия является парной? |
если величина коэффициента корреляции указывает на тесную связь переменных |
нет |
|
32. Можно ли на основании решения Excel прогнозировать изменение Y в зависимости от изменения X? |
можно, только если построенная регрессионная модель является качественной |
да |
|
40. Значения a и b для поиска уравнения регрессионной зависимости берутся |
из расчетов по методу наименьших квадратов |
да |
|
44. В уравнении регрессии независимая переменная обычно обозначается как |
у |
нет |
|
50. Сколько зависимых переменных может быть в уравнении регрессии? |
в парной регрессии - не более двух, во множественной - сколько угодно |
нет |
|
55. В результатах решения задачи коэффициент регрессии а отображается как: |
Множественный R |
нет |
|
56. В уравнении y = a + bx величина коэффициента а отражает |
значимость или незначимость переменной у |
нет |
|
58. Чему будет равен Y в парной линейной регрессии, если Y-пересечение = 5, b = 7, х = 10? |
75 |
да |
|
61. Чему будет равен Y в множественной линейной регрессии, если Y-пересечение = 10, b1 = 1, b2 = 2, х1 = 3, x2 = 4? |
14 |
нет |
|
68. В уравнении y = a + bx незначимость коэффициента регрессии b означает, что |
влияние переменной х на коэффициент b отсутствует |
нет |
|
73. Что означает статистическая незначимость параметра (коэффициента) регрессии? |
слабую связь в построенном уравнении регрессии |
нет |
|
75. Какая величина «Р-значения» подтверждает влияние х на у? |
Р-значение для него положительно |
нет |
|
90. Нулевая гипотеза для коэфициента детерминации отвергается при |
Значимости F, большей 5% |
нет |
|
91. Что означает незначимость коэффициента детерминации? |
что рассчитанный коэффициент детерминации не достоверен |
да |
|
98. Как рассчитывается коэффициент детерминации? |
как доля объясненной регрессией дисперсии в общей дисперсии зависимой переменной |
да |
|
99. О чем свидетельствует близкое к 1 значение коэффициента детерминации? |
о наличии тесной связи между изучаемыми показателями |
да |
|
Вопрос |
Ответ |
Верно |
|
10. Что означает наличие прямой связи между переменными х и у? |
что графики переменных х и у являются прямыми линиями |
нет |
|
100. Величина RSS показывает |
величину дисперсии зависимой переменной, не объясненной регрессией |
нет |
|
104. Что такое остаток? |
разность между 0,7 и величиной коэффициента корреляции |
нет |
|
111. В каких случаях не обязательно удаление статистических выбросов? |
в случае сильной связи в регрессионной модели |
да |
|
112. В каких случаях необходимо удаление статистических выбросов? |
в случае низкого значения коэффициента корреляции |
да |
|
115. Для чего в регрессионную модель вводятся бинарные переменные? |
для перехода от нелинейного вида зависимости к линейному |
нет |
|
117. Фиктивная переменная - это |
показатель тесноты связи в уравнении регрессии |
нет |
|
119. Уравнение регрессии, содержащее бинарные переменные, является |
регрессионной моделью |
да |
|
122. Можно ли использовать бинарные переменные в парной регрессии? |
да, если объясняемых переменных более 2 |
нет |
|
124. Может ли бинарная переменная быть неза висимой переменной регрессионной модели? |
может только в случае, если регрессионная модель линейна |
нет |
|
128. Незначимость бинарной переменной означает |
отсутствие тесной связи между зависимой и объясняющими переменными модели |
нет |
|
13. Для определения тесноты линейной связи между двумя факторами необходимо |
рассчитать параметры нормального распределения обоих факторов |
нет |
|
16. Регрессионный анализ оценивает |
формулу связи двух или нескольких переменных |
да |
|
23. Решение по МНК в пакете Excel можно получить при помощи |
опций Анализ данных - Регрессия |
да |
|
25. Для чего применяется МНК? |
для перехода от нелинейной формы зависимости переменных к линейной |
нет |
|
30. Какого вида регрессионная зависимость между переменными не может существовать? |
тесная, прямая |
нет |
|
33. После записи уравнения регрессии необходимо |
рассчитать сумму квадратов остатков |
нет |
|
42. Какие величины служат для записи уравнения регрессии? |
Множественный R и Значимость F |
нет |
|
46. В уравнении регрессии параметры обычно обозначаются как |
х и у |
нет |
|
48. В уравнении регрессионной зависимости может быть только |
несколько зависимых и одна или несколько независимых переменных |
нет |
|
52. В уравнении y = a + bx коэффициент а является |
коэффициентом корреляции |
нет |
|
54. В уравнении регрессии параметры регрессии обычно обозначаются как |
а и b |
да |
|
77. Что следует делать, если коэффициент регрессии не значим? |
увеличить количество зависимых переменных |
нет |
|
81. Что проверяется с помощью коэффициента корреляции? |
теснота связи между факторами в уравнении регрессии |
да |
|
93. Что необходимо сделать в случае незначимости коэффициента детерминации? |
удалить из модели константу а |
нет |
|
Вопрос |
Ответ |
Верно |
|
100. Величина RSS показывает |
величину коэффициента детерминации |
нет |
|
101. Величина ТSS показывает |
величину дисперсии зависимой переменной, объясненной регрессией |
нет |
|
108. Что такое статистический выброс? |
незначимый коэффициент корреляции |
нет |
|
11. Что означает наличие обратной связи между переменными х и у? |
что график зависимости между х и у не является прямой линией |
нет |
|
111. В каких случаях не обязательно удаление статистических выбросов? |
в случае сильной связи в регрессионной модели |
да |
|
116. Что такое бинарная переменная? |
переменная, принимающая значения "0" или "1" при наличии или отсутствии признака |
да |
|
119. Уравнение регрессии, содержащее бинарные переменные, является |
регрессионной моделью |
да |
|
120. Какие значения может принимать фиктивная переменная? |
0 и 1 |
да |
|
124. Может ли бинарная переменная быть независимой переменной регрессионной модели? |
да, конечно |
да |
|
14. Взаимозависимости экономических переменных часто описываются |
линейным уравнением |
да |
|
19. Регрессия у на х - это |
коэффициент корреляции между у и х |
нет |
|
20. Какой метод позволяет определить оценки параметров регрессии? |
метод наименьших квадратов |
да |
|
25. Для чего применяется МНК? |
для оценки параметров регрессии |
да |
|
28. В каком случае регрессия является множественной? |
если в ур-е регрессии входит одна зависимая и множество независимых переменных |
да |
|
42. Какие величины служат для записи уравнения регрессии? |
коэффициенты регрессии |
да |
|
44. В уравнении регрессии независимая переменная обычно обозначается как |
a |
нет |
|
45. В уравнении регрессии факторы обычно обозначаются как |
х и у |
да |
|
48. В уравнении регрессионной зависимости может быть только |
одна зависимая и одна независимая переменная |
нет |
|
55. В результатах решения задачи коэффициент регрессии а отображается как: |
Значимость F |
нет |
|
57. В результатах регрессионного анализа Y-пересечение - это |
величина остатка |
нет |
|
62. Чему будет равен Y в множественной линейной регрессии, если Y-пересечение = 6, b1 = 2, b2 = 5, х1 = 8, x2 = 4? |
42 |
да |
|
65. Как в уравнении регрессии интерпретируется коэффициент перед переменной х? |
показывает статистическую значимость переменной х |
нет |
|
9. В эконометрических задачах математическая модель |
это уравнение регрессии или система уравнений регрессии |
да |
|
90. Нулевая гипотеза для коэфициента детерминации отвергается при |
Значимости F, меньшей или равной 5% |
да |
|
99. О чем свидетельствует близкое к 1 значение коэффициента детерминации? |
о наличии тесной связи между изучаемыми показателями |
да |
|
101. Величина ТSS показывает |
величину стандартной ошибки уравнения регрессии |
нет |
|
116. Зачем в регрессионном анализе используются бинарные переменные? |
для фиксации свойств найденной регрессии |
нет |
|
121. Можно ли использовать бинарные переменные в множественной регрессии? |
да |
да |
|
130. В каких случаях производится исключение бинарных переменных из модели? |
в случае слабой связи в модели |
нет |
|
27. В каком случае регрессия является парной? |
если все коэффициенты регрессии положительны |
нет |
|
28. В каком случае регрессия является множественной? |
если в ур-е регрессии входит одна зависимая и множество независимых переменных |
да |
|
29. Какие виды регрессионных зависимостей существуют? |
парная, множественная, линейная, нелинейная |
да |
|
3. Эконометрика занимается изучением |
статистических таблиц распределений случайных величин |
нет |
|
30. Какого вида регрессионная зависимость между переменными не может существовать? |
прямая, парная, нелинейная |
нет |
|
31. Что является математической моделью эконометрической задачи? |
совокупность числовых характеристик переменных Х и Y |
нет |
|
33. После записи уравнения регрессии необходимо |
определить зависимые и независимые переменные |
нет |
|
34. Регрессионная модель считается качественной при обязательном выполнении следующих условий: |
связь в модели тесная, объясняющие переменные значимы, наблюдений достаточно |
да |
|
44. В уравнении регрессии независимая переменная обычно обозначается как |
b |
нет |
|
49. Сколько объясняющих переменных может быть в уравнении регрессии? |
только одна |
нет |
|
53. В уравнении y = a + bx коэффициент b является |
коэффициентом корреляции |
нет |
|
61. Чему будет равен Y в множественной линейной регрессии, если Y-пересечение = 10, b1 = 1, b2 = 2, х1 = 3, x2 = 4? |
24 |
нет |
|
64. В уравнении регрессии у = a + bx коэффициент а показывает |
является ли связь между зависимой и независимыми переменными тесной |
нет |
|
65. Как в уравнении регрессии интерпретируется коэффициент перед переменной х? |
показывает величину изменения у при единичном изменении х |
да |
|
7. Что может быть выполнено с помощью эконометрической модели? |
управление программными средствами, предназначенными для экономических расчетов |
нет |
|
75. Какая величина «Р-значения» подтверждает влияние х на у? |
Р-значение для него меньше 0,05 |
да |
|
81. Что проверяется с помощью коэффициента корреляции? |
теснота связи между факторами в уравнении регрессии |
да |
|
84. Тесная связь между перменными модели констатируется в том случае, если |
коэффициент корреляции по модулю не меньше 0,7 |
да |
|
86. В результатах решения задачи в Excel коэффициент корреляции отображается как: |
переменная Х1 |
нет |
|
89. Для чего служит величина "Значимость F"? |
является одним из коэффициентов уравнения регрессии |
нет |
|
92. В каком случае коэффициент детерминации может быть не достоверен? |
в случае, если единицы измерения переменных Х и Y различны |
нет |
|
Вопрос |
Ответ |
Верно |
||
|
102. Величина ЕSS показывает |
величину коэффициента корреляции |
нет |
||
|
111. В каких случаях не обязательно удаление статистических выбросов? |
в случае сильной связи в регрессионной модели |
да |
||
|
113. Каковы последствия удаления статистических выбросов в регрессионном анализе? |
увеличение тесноты связи в модели |
да |
||
|
124. Может ли бинарная переменная быть независимой переменной регрессионной модели? |
да, конечно |
да |
||
|
128. Незначимость бинарной переменной означает |
отсутствие Р-значения для этой переменной |
нет |
||
|
129. Статистическая значимость бинарной переменной означает |
подтвержденное влияние данного качественного признака на зависимую переменную |
да |
||
|
26. Для оценки формы связи между переменными служит |
коэффициент корреляции |
нет |
||
|
27. В каком случае регрессия является парной? |
если в уравнение регрессии входит пара зависимых и пара независимых переменных |
нет |
||
|
29. Какие виды регрессионных зависимостей существуют? |
парная, множественная, линейная, нелинейная |
да |
||
|
32. Можно ли на основании решения Excel прогнозировать изменение Y в зависимости от изменения X? |
можно, только если построенная регрессионная модель является качественной |
да |
||
|
33. После записи уравнения регрессии необходимо |
оценить качество полученного уравнения |
да |
||
|
34. Регрессионная модель считается качественной при обязательном выполнении следующих условий: |
связь в модели тесная, объясняющие переменные значимы, наблюдений достаточно |
да |
||
|
43. В уравнении регрессии зависимая переменная обычно обозначается как |
у |
да |
||
|
45. В уравнении регрессии факторы обычно обозначаются как |
х и у |
да |
||
|
51. В уравнении y = a + bx коэффициенты а и b - это: |
RSS и ESS |
нет |
||
|
53. В уравнении y = a + bx коэффициент b является |
параметром регрессии |
да |
||
|
6. Математическая модель экономического объекта предназначена для |
накапливания статистических данных |
нет |
||
|
61. Чему будет равен Y в множественной линейной регрессии, если Y-пересечение = 10, b1 = 1, b2 = 2, х1 = 3, x2 = 4? |
21 |
да |
||
|
64. В уравнении регрессии у = a + bx коэффициент а показывает |
величину случайной составляющей в уравнении регрессии |
нет |
||
|
66. В уравнении регрессии у = a + bx коэффициент b показывает |
является ли связь между зависимой и независимыми переменными тесной |
нет |
||
|
7. Что может быть выполнено с помощью эконометрической модели? |
прогнозирование поведения изучаемого экономического объекта |
да |
||
|
79. Какой показатель характеризует тесноту связи в уравнении регрессии? |
коэффициент корреляции |
да |
||
|
86. В результатах решения задачи в Excel коэффициент корреляции отображается как: |
Множественный R |
да |
||
|
94. Причиной недостоверности коэффициента детерминации может служить |
недостаточное количество наблюдений |
да |
||
|
97. Что показывает коэффициент детерминации? |
объясненную регрессией долю дисперсии независимой переменной х |
нет |
||
|
Вопрос |
Ответ |
Верно |
||
|
1. Что является предметом изучения эконометрики? |
факторы, формирующие развитие экономических явлений и процессов |
да |
||
|
100. Величина RSS показывает |
общий разброс зависимой переменной вокруг ее среднего значения |
нет |
||
|
102. Величина ЕSS показывает |
величину дисперсии зависимой переменной, объясненной регрессией |
нет |
||
|
107. Что такое статистический выброс? |
наблюдение, для которого совпадают реальное и расчетное значения y |
нет |
||
|
109. Какое наблюдение считается статистическим выбросом? |
наблюдение, величина стандартного остатка которого по модулю больше 2 |
да |
||
|
118. Бинарная переменная является |
показателем качества регрессионной модели |
нет |
||
|
122. Можно ли использовать бинарные переменные в парной регрессии? |
да, если объясняемых переменных более 2 |
нет |
||
|
126. Что означает отрицательный коэффициент при бинарной переменной? |
что бинарная переменная не значима |
нет |
||
|
128. Незначимость бинарной переменной означает |
отсутствие влияния данного качественного признака на зависимую переменную |
да |
||
|
18. Функция, описывающая корреляционную зависимость между х и у, называется |
регрессией у на х |
да |
||
|
34. Регрессионная модель считается качественной при обязательном выполнении следующих условий: |
связь в модели тесная, объясняющие переменные значимы, наблюдений достаточно |
да |
||
|
36. Уравнение регрессии оценивает |
сумму квадратов отклонений реальных значений от расчетных |
нет |
||
|
4. Для решения эконометрических задач необходимо |
наличие специализированных программных средств |
нет |
||
|
43. В уравнении регрессии зависимая переменная обычно обозначается как |
у |
да |
||
|
48. В уравнении регрессионной зависимости может быть только |
одна зависимая и одна или несколько независимых переменных |
да |
||
|
53. В уравнении y = a + bx коэффициент b является |
коэффициентом корреляции |
нет |
||
|
6. Математическая модель экономического объекта предназначена для |
накапливания статистических данных |
нет |
||
|
61. Чему будет равен Y в множественной линейной регрессии, если Y-пересечение = 10, b1 = 1, b2 = 2, х1 = 3, x2 = 4? |
21 |
да |
||
|
72. Значимость коэффициентов регрессии определяется с помощью: |
величины Значимости F |
нет |
||
|
8. Математической моделью в эконометрических задачах является |
уравнение регрессии или система уравнений регрессии |
да |
||
|
80. С помощью какой величины определяется теснота связи в уравнении регрессии? |
с помощью величины Значимость F |
нет |
||
|
81. Что проверяется с помощью коэффициента корреляции? |
теснота связи между факторами в уравнении регрессии |
да |
||
|
84. Тесная связь между перменными модели констатируется в том случае, если |
все Р-значения меньше 0,05 |
нет |
||
|
86. В результатах решения задачи в Excel коэффициент корреляции отображается как: |
переменная Х1 |
нет |
||
|
95. В каком случае коэффициент детерминации считается незначимым? |
если величина "Нормированный R-квадрат" больше 0,5 |
нет |
||
StudFiles.ru
Вычисление линейной регрессии
7.1. Линейный регрессионный анализ заключается в подборе графика для набора наблюдений с помощью метода наименьших квадратов. Регрессионный анализ позволяет установить функциональную зависимость между некоторой случайной величиной Y и некоторыми влияющими на Y величинами X. Такая зависимость получила название уравнения регрессии. Различают простую (y=m*x+b) и множественную (y=m1*x1+m2*x2+... + mk*xk+b) регрессию линейного и нелинейного типа.
Для оценки степени связи между величинами используется коэффициент множественной корреляции R Пирсона (корреляционное отношение), который может принимать значения от 0 до 1. R=0, если между величинами нет никакой связи, и R=1, если между величинами имеется функциональная связь. В большинстве случаев R принимает промежуточные значения от 0 до 1. Величина R2 называется коэффициентом детерминации.
Задачей построения регрессионной зависимости является нахождение вектора коэффициентов M модели множественной линейной регрессии, при котором коэффициент R принимает максимальное значение.
Для оценки значимости R применяется F-критерий Фишера, вычисляемый по формуле:
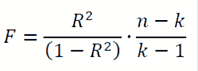
где n – количество экспериментов; k – число коэффициентов модели. Если F превышает некоторое критическое значение для данных n и k и принятой доверительной вероятности, то величина R считается существенной.
7.2. Инструмент Регрессия из Пакета анализа позволяет вычислить следующие данные:
· коэффициенты линейной функции регрессии– методом наименьших квадратов; вид функции регрессии определяется структурой исходных данных;
· коэффициент детерминации и связанные с ним величины (таблица Регрессионная статистика);
· дисперсионную таблицу и критериальную статистику для проверки значимости регрессии (таблица Дисперсионный анализ);
· среднеквадратическое отклонение и другие его статистические характеристики для каждого коэффициента регрессии, позволяющие проверить значимость этого коэффициента и построить для него доверительные интервалы;
· значения функции регрессии и остатки – разности между исходными значениями переменной Y и вычисленными значениями функции регрессии (таблица Вывод остатка);
· вероятности, соответствующие упорядоченным по возрастанию значениям переменной Y (таблица Вывод вероятности).
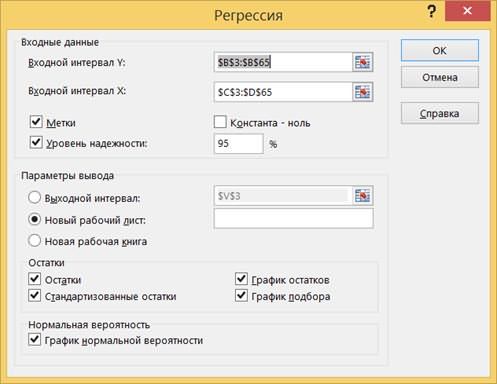
7.3. Вызовите инструмент создания выборки через Данные> Анализ данных> Регрессия.

7.4. В поле Входной интервал Y вводится адрес диапазона, содержащего значения зависимой переменной Y. Диапазон должен состоять из одного столбца.
В поле Входной интервал X вводится адрес диапазона, содержащего значения переменной X. Диапазон должен состоять из одного или нескольких столбцов, но не более чем из 16 столбцов. Если указанные в полях Входной интервал Y и Входной интервал X диапазоны включают заголовки столбцов, то необходимо установить флажок опции Метки – эти заголовки будут использованы в выходных таблицах, сгенерированных инструментом Регрессия.
Флажок опции Константа - ноль следует установить, если в уравнении регрессии константа b принудительно полагается равной нулю.
Опция Уровень надежности устанавливается тогда, когда необходимо построить доверительные интервалы для коэффициентов регрессии с доверительным уровнем, отличным от 0.95, который используется по умолчанию. После установки флажка опции Уровень надежности становится доступным поле ввода, в котором вводится новое значение доверительного уровня.
В области Остатки имеются четыре опции: Остатки, Стандартизованные остатки, График остатков и График подбора. Если установлена хотя бы одна из них, то в выходных результатах появится таблица Вывод остатка, в которой будут выведены значения функции регрессии и остатки – разности между исходными значениями переменной Y и вычисленными значениями функции регрессии. В области Нормальная вероятность имеется одна опция – График нормальной вероятности; ее установка порождает в выходных результатах таблицу Вывод вероятности и приводит к построению соответствующего графика.
7.5. Установите параметры в соответствии с рисунком. Проверьте, что в качестве величины Y указана первая переменная (включая ячейку с названием), и в качестве величины X указаны две остальные переменные (включая ячейки с названиями). Нажмите OK.
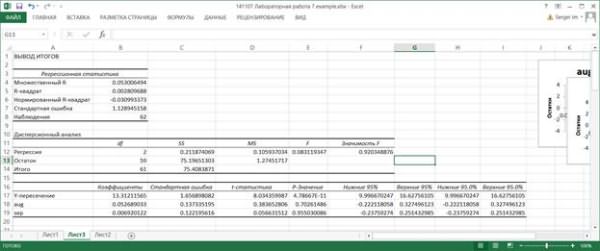
7.6. В таблице Регрессионная статистика приводятся следующие данные.
Множественный R – корень из коэффициента детерминации R2, приведенного в следующей строке. Другое название этого показателя – индекс корреляции, или множественный коэффициент корреляции.
R-квадрат – коэффициент детерминации R2; вычисляется как отношение регрессионной суммы квадратов (ячейка С12) к полной сумме квадратов (ячейка С14).
Нормированный R-квадрат вычисляется по формуле
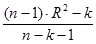
где n – количество значений переменной Y, k – количество столбцов во входном интервале переменной X.
Стандартная ошибка – корень из остаточной дисперсии (ячейка D13).
Наблюдения – количество значений переменной Y.
7.7. В Дисперсионной таблице в столбце SS приводятся суммы квадратов, в столбце df – число степеней свободы. в столбце MS – дисперсии. В строке Регрессия в столбце f вычислено значение критериальной статистики для проверки значимости регрессии. Это значение вычисляется как отношение регрессионной дисперсии к остаточной (ячейки D12 и D13). В столбце Значимость F вычисляется вероятность полученного значения критериальной статистики. Если эта вероятность меньше, например, 0.05 (заданного уровня значимости), то гипотеза о незначимости регрессии (т.е. гипотеза о том, что все коэффициенты функции регрессии равны нулю) отвергается и считается, что регрессия значима. В данном примере регрессия незначима.
7.8. В следующей таблице, в столбце Коэффициенты, записаны вычисленные значения коэффициентов функции регрессии, при этом в строке Y-пересечение записано значение свободного члена b. В столбце Стандартная ошибка вычислены среднеквадратические отклонения коэффициентов.
В столбце t-статистика записаны отношения значений коэффициентов к их среднеквадратическим отклонениям. Это значения критериальных статистик для проверки гипотез о значимости коэффициентов регрессии.
В столбце P-Значение вычисляются уровни значимости, соответствующие значениям критериальных статистик. Если вычисленный уровень значимости меньше заданного уровня значимости (например, 0.05). то принимается гипотеза о значимом отличии коэффициента от нуля; в противном случае принимается гипотеза о незначимом отличии коэффициента от нуля. В данном примере только коэффициент b значимо отличается от нуля, остальные – незначимо.
В столбцах Нижние 95%и Верхние 95% приводятся границы доверительных интервалов с доверительным уровнем 0.95. Эти границы вычисляются по формулам
Нижние 95% = Коэффициент - Стандартная ошибка * tα;
Верхние 95% = Коэффициент + Стандартная ошибка * tα.
Здесь tα – квантиль порядка α распределения Стьюдента с (n-k-1) степенью свободы. В данном случае α = 0.95. Аналогично вычисляются границы доверительных интервалов в столбцах Нижние 90.0% и Верхние 90.0%.
7.9. Рассмотрим таблицу Вывод остатка из выходных результатов. Эта таблица появляется в выходных результатах только тогда, когда установлена хотя бы одна опция в области Остатки диалогового окна Регрессия.
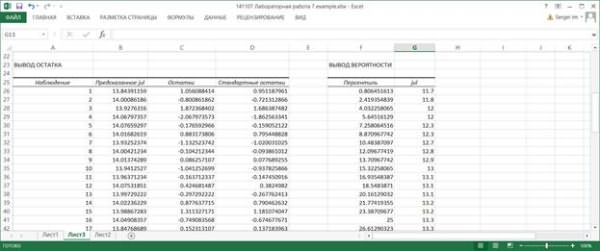
В столбце Наблюдение приводятся порядковые номера значений переменной Y.
В столбце Предсказанное Y вычисляются значения функции регрессии уi = f(хi) для тех значений переменной X, которым соответствует порядковый номер i в столбце Наблюдение.
В столбце Остатки содержатся разности (остатки) εi=Y-уi , а в столбце Стандартные остатки – нормированные остатки, которые вычисляются как отношения εi / sε. где sε – среднеквадратическое отклонение остатков. Квадрат величины sε вычисляется по формуле
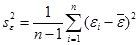
где 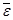 – среднее остатков. Величину
– среднее остатков. Величину 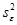 можно вычислить как отношение двух значений из дисперсионной таблицы: суммы квадратов остатков (ячейка С13) и степени свободы из строки Итого (ячейка В14).
можно вычислить как отношение двух значений из дисперсионной таблицы: суммы квадратов остатков (ячейка С13) и степени свободы из строки Итого (ячейка В14).
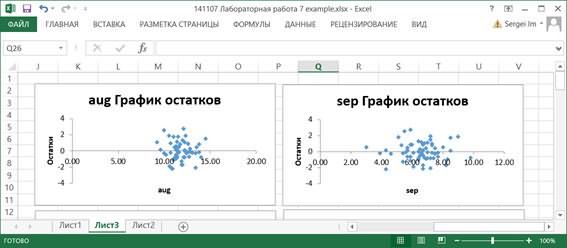
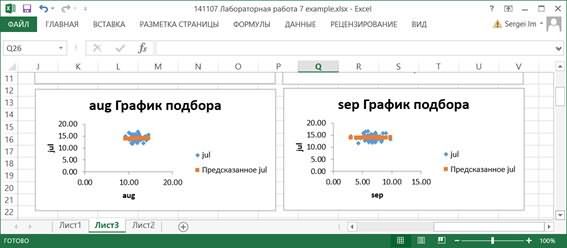
7.10. По значениям таблицы Вывод остатка строятся два типа графиков: графики остатков и графики подбора (если установлены соответствующие опции в области Остатки диалогового окна Регрессия). Они строятся для каждого компонента переменной X в отдельности.
На графиках остатков отображаются остатки, т.е. разности между исходными значениями Y и вычисленными по функции регрессии для каждого значения компонента переменной X.
На графиках подбора отображаются как исходные значения Y, так и вычисленные значения функции регрессии для каждого значения компонента переменной X.
7.11. Последней таблицей выходных результатов является таблица Вывод вероятности. Она появляется, если в диалоговом окне Регрессия установлена опция График нормальной вероятности.
Значения в столбце Персентиль вычисляются следующим образом. Вычисляется шаг h = (1/n)*100%, первое значение равно h/2, последнее равно 100-h/2. Начиная со второго значения каждое последующее значение равно предыдущему, к которому прибавлен шаг h.
В столбце Y приведены значения переменной Y, упорядоченные по возрастанию. По данным этой таблицы строится так называемый график нормального распределения. Он позволяет визуально оценить степень линейности зависимости между переменными X и Y.
8.Дисперсионный анализ
8.1. Пакет анализа позволяет провести три вида дисперсионного анализа. Выбор конкретного инструмента определяется числом факторов и числом выборок в исследуемой совокупности данных.
Однофакторный дисперсионный анализ используется для проверки гипотезы о сходстве средних значений двух или более выборок, принадлежащих одной и той же генеральной совокупности.
Двухфакторный дисперсионный анализ с повторениями представляет собой более сложный вариант однофакторного анализа, включающий более чем одну выборку для каждой группы данных.
Двухфакторный дисперсионный анализ без повторения представляет собой двухфакторный анализ дисперсии, не включающий более одной выборки на группу. Он используется для проверки гипотезы о том, что средние значения двух или нескольких выборок одинаковы (выборки принадлежат одной и той же генеральной совокупности).
8.2. Однофакторный дисперсионный анализ
8.2.1. Подготовим данные для анализа. Создайте новый лист и скопируйте на него колонки A, B, C, D. Удалите первые две строки. Подготовленные данные можно использовать для проведения Однофакторного дисперсионного анализа.
8.2.2. Вызовите инструмент создания выборки через Данные> Анализ данных> Однофакторный дисперсионный анализ.Заполните в соответствии с рисунком. Нажмите OK.
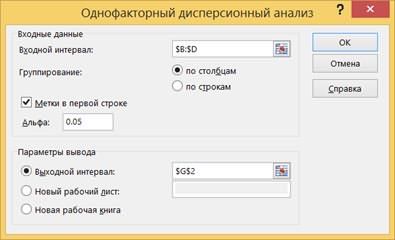
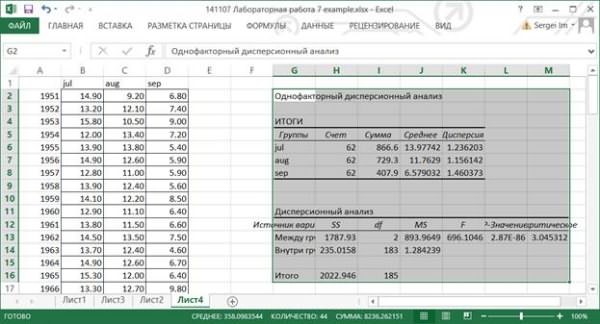
8.2.3. Рассмотрим таблицу Итоги: Счет – число повторений, Сумма – сумма значений показателя по строкам, Дисперсия – частная дисперсия показателя.
8.2.4. Таблица Дисперсионный анализ: первая колонка Источник вариации содержит наименование дисперсий, SS – сумма квадратов отклонений, df – степень свободы, MS – средний квадрат, F-критерий фактического F распределения. P-значение – вероятность того, что дисперсия, воспроизводимая уравнением, равна дисперсии остатков. Оно устанавливает вероятность того, что полученная количественная определенность взаимосвязи между факторами и результатом может считаться случайной. F-критическое – это значение F теоретического, которое впоследствии сравнивается с F фактическим.
8.2.5. Нулевая гипотеза о равенстве математических ожиданий всех выборок принимается, если выполняется неравенство F-критерий < F-критическое. эту гипотезу следует отвергнуть. В данном случае средние значения выборок – значимо различаются.
studopedia.ru
4. Уровни статистической значимости
Уровень значимости - это вероятность того, что мы сочли различия существенными, а они на самом деле случайны.
Когда мы указываем, что различия достоверны на 5%-ом уровне значимости, или при р0,05, то мы имеем виду, что вероятность того, что они все-таки недостоверны, составляет 0,05.
Когда мы указываем, что различия достоверны на 1%-ом уровне значимости, или при р0,01, то мы имеем в виду, что вероятность того, что они все-таки недостоверны, составляет 0,01.
Если перевести все это на более формализованный язык, то уровень значимости - это вероятность отклонения нулевой гипотезы, в то время как она верна.
Ошибка, состоящая в той, что мы отклонили нулевую гипотезу, в то время как она верна, называется ошибкой 1 рода. (См. Табл. 1)
 Табл. 1. Нулевая и альтернативные гипотезы и возможные состояния проверки.
Табл. 1. Нулевая и альтернативные гипотезы и возможные состояния проверки.
Вероятность такой ошибки обычно обозначается как α. В сущности, мы должны были бы указывать в скобках не р0,05 или р0,01, а α0,05 или α0,01.
Если вероятность ошибки - это α, то вероятность правильного решения: 1—α. Чем меньше α, тем больше вероятность правильного решения.
Исторически сложилось так, что в психологии принято считать низшим уровнем статистической значимости 5%-ый уровень (р≤0,05): достаточным – 1%-ый уровень (р≤0,01) и высшим 0,1%-ый уровень (р≤0,001), поэтому в таблицах критических значений обычно приводятся значения критериев, соответствующих уровням статистической значимости р≤0,05 и р≤0,01, иногда - р≤0,001. Для некоторых критериев в таблицах указан точный уровень значимости их разных эмпирических значений. Например, для φ*=1,56 р=О,06.
До тех пор, однако, пока уровень статистической значимости не достигнет р=0,05, мы еще не имеем права отклонить нулевую гипотезу. Мы будем придерживаться следующего правила отклонения гипотезы об отсутствии различий (Но) и принятия гипотезы о статистической достоверности различий (Н1).
Правило отклонения Hо и принятия h1
Если эмпирическое значение критерия равняется критическому значению, соответствующему р≤0,05 или превышает его, то H0 отклоняется, но мы еще не можем определенно принять H1.
Если эмпирическое значение критерия равняется критическому значению, соответствующему р≤0,01 или превышает его, то H0 отклоняется и принимается Н1.
Исключения: критерий знаков G, критерий Т Вилкоксона и критерий U Манна-Уитни. Для них устанавливаются обратные соотношения.
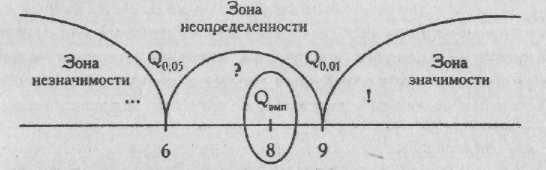
Рис. 4. Пример «оси значимости» для критерия Q Розенбаума.
Критические значения критерия обозначены как Qо,о5 и Q0,01, эмпирическое значение критерия как Qэмп. Оно заключено в эллипс.
Вправо от критического значения Q0,01 простирается "зона значимости" - сюда попадают эмпирические значения, превышающие Q 0,01 и, следовательно, безусловно, значимые.
Влево от критического значения Q 0,05, простирается "зона незначимости", - сюда попадают эмпирические значения Q, которые ниже Q 0,05, и, следовательно, безусловно незначимы.
Мы видим, что Q0,05=6; Q0,01=9; Qэмп.=8;
Эмпирическое значение критерия попадает в область между Q0,05 и Q0,01. Это зона "неопределенности": мы уже можем отклонить гипотезу о недостоверности различий (Н0), но еще не можем принять гипотезы об их достоверности (H1).
Практически, однако, исследователь может считать достоверными уже те различия, которые не попадают в зону незначимости, заявив, что они достоверны при р0,05, или указав точный уровень значимости полученного эмпирического значения критерия, например: р=0,02. С помощью стандартных таблиц, которые есть во всех учебниках по математическим методам это можно сделать по отношению к критериям Н Крускала-Уоллиса, χ2rФридмана, L Пейджа, φ* Фишера.
Уровень статистической значимости или критические значения критериев определяются по-разному при проверке направленных и ненаправленных статистических гипотез.
При направленной статистической гипотезе используется односторонний критерий, при ненаправленной гипотезе - двусторонний критерий. Двусторонний критерий более строг, поскольку он проверяет различия в обе стороны, и поэтому то эмпирическое значение критерия, которое ранее соответствовало уровню значимости р0,05, теперь соответствует лишь уровню р0,10.
Нам не придется всякий раз самостоятельно решать, использует ли он односторонний или двухсторонний критерий. Таблицы критических значений критериев подобраны таким образом, что направленным гипотезам соответствует односторонний, а ненаправленным - двусторонний критерий, и приведенные значения удовлетворяют тем требованиям, которые предъявляются к каждому из них. Исследователю необходимо лишь следить за тем, чтобы его гипотезы совпадали по смыслу и по форме с гипотезами, предлагаемыми в описании каждого из критериев.
StudFiles.ru
Понятие уровня статистической значимости
Первоначально всегда выдвигается гипотеза Н0. В процессе применения конкретного статистического метода перед психологом стоит дилемма: принять гипотезу Н0 или отклонить её и принять альтернативную гипотезу Н1. Очевидно, что возможны 4 варианта, которые можно оформить в виде таблицы.
| Решение | Верна Н0 | Верна Н1 |
| Н1 отклоняется | Ошибка 1рода | Правильное решение |
| Н0 не отклоняется | Правильное решение | Ошибка2 рода |
Понятно, что исследователя всегда интересует вопрос, насколько будет правильным его решение отклонить гипотезу Н0. Иными словами, какова вероятность ошибочного отклонения гипотезы Н0.
Уровень значимости – это вероятность ошибочного отклонения нулевой гипотезы, иными словами вероятность ошибки 1 рода.
Исторически сложилось так, что в прикладных науках, использующих статистику и в частности в психологии считается, что низшим уровнем значимости является уровень
Р = 0,05 ; достаточным уровнем значимости Р = 0,01 и высшим уровнем значимости Р = 0,001
(или Р = 5%; Р = 1%; Р = 0,1%).
Вероятность Р = 0,05 означает, 5 ошибок на 100 случаев или 1 ошибка на 20 случаев.
Вероятность Р = 0,01 означает 1 ошибку на 100 случаев.
Мы будем пользоваться уровнем значимости Р = 0,05 и Р = 0,01
 17. Ось значимости.
17. Ось значимости.
Зона не значимости зона значимости
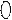 Зона неопределённости
Зона неопределённости
Р = 0,05Р = 0,01
Ось значимости начинается с нуля, который обычно не отмечается. Полученные в результате применения конкретного метода эмпирические значения располагаются на оси значимости.
Критические значения находятся из специальных таблиц.
Эмпирические значения отмечают на оси без учёта знака.  -
-  .
.
Если эмпирическое значение попадает в зону незначимости, то применяется Н0.
Если эмпирическое значение попадает в зону значимости, то Н0 отклоняется и принимается Н1.
Если эмпирическое значение попадает в зону неопределённости, то принимается Н0, но на уровне 5% значимости она может быть отклонена и принята гипотеза Н1.
Если эмпирическое значение совпадает с критическим, то попадает в следующую зону.
studopedia.ru
Читайте также
 Аутентичность значение слова
Аутентичность значение слова 1515 На часах значение
1515 На часах значение Чувак значение слова с еврейского
Чувак значение слова с еврейского Барыга значение слова википедия
Барыга значение слова википедия 16 16 Значение времени
16 16 Значение времени Семен значение имени характер и судьба
Семен значение имени характер и судьба 15 15 Значение
15 15 Значение 20 20 Значение
20 20 Значение Безопасное значение темпа роста прибыли должно быть
Безопасное значение темпа роста прибыли должно быть 23 23 Значение
23 23 Значение 15 51 Значение времени
15 51 Значение времени Бабочка значение
Бабочка значение
 Аутентичность значение слова
Аутентичность значение слова 1515 На часах значение
1515 На часах значение Чувак значение слова с еврейского
Чувак значение слова с еврейского Барыга значение слова википедия
Барыга значение слова википедия 16 16 Значение времени
16 16 Значение времени Семен значение имени характер и судьба
Семен значение имени характер и судьба 15 15 Значение
15 15 Значение 20 20 Значение
20 20 Значение Безопасное значение темпа роста прибыли должно быть
Безопасное значение темпа роста прибыли должно быть 23 23 Значение
23 23 Значение 15 51 Значение времени
15 51 Значение времени Бабочка значение
Бабочка значение