Коэффициент корреляции
 Коэффициент корреляции – это величина, которая может варьировать в пределах от +1 до –1. В случае полной положительной корреляции этот коэффициент равен плюс 1 (говорят о том, что при увеличении значения одной переменной увеличивается значение другой переменной), а при полной отрицательной – минус 1 (свидетельствуют об обратной связи, т.е. При увеличении значений одной переменной, значения другой уменьшаются).
Коэффициент корреляции – это величина, которая может варьировать в пределах от +1 до –1. В случае полной положительной корреляции этот коэффициент равен плюс 1 (говорят о том, что при увеличении значения одной переменной увеличивается значение другой переменной), а при полной отрицательной – минус 1 (свидетельствуют об обратной связи, т.е. При увеличении значений одной переменной, значения другой уменьшаются).
 Пр1.:
Пр1.:
График зависимости застенчивости и дипресивности. Как видим, точки (испытуемые) расположены не хаотично, а выстраиваются вокруг одной линии, причём, глядя на эту линию можно сказать, что чем выше у человека выражена застенчивость, тем больше депрессивность, т. е. эти явления взаимосвязаны.
 Пр2.: График для Застенчивости и Общительности. Мы видим, что с увеличением застенчивости общительность уменьшается. Их коэффициент корреляции -0,43. Таким образом, коэффициент корреляции больший от 0 до 1 говорит о прямопропорциональной связи (чем больше… тем больше…), а коэффициент от -1 до 0 о обратнопропорциональной (чем больше… тем меньше…)
Пр2.: График для Застенчивости и Общительности. Мы видим, что с увеличением застенчивости общительность уменьшается. Их коэффициент корреляции -0,43. Таким образом, коэффициент корреляции больший от 0 до 1 говорит о прямопропорциональной связи (чем больше… тем больше…), а коэффициент от -1 до 0 о обратнопропорциональной (чем больше… тем меньше…)
 В случае если коэффициент корреляции равен 0, обе переменные полностью независимы друг от друга.
В случае если коэффициент корреляции равен 0, обе переменные полностью независимы друг от друга.
Корреляционная связь - это связь, где воздействие отдельных факторов проявляется только как тенденция (в среднем) при массовом наблюдении фактических данных. Примерами корреляционной зависимости могут быть зависимости между размерами активов банка и суммой прибыли банка, ростом производительности труда и стажем работы сотрудников.
Используется две системы классификации корреляционных связей по их силе: общая и частная.
Общая классификация корреляционных связей:1) сильная, или тесная при коэффициенте корреляции r>0,70;2) средняя при 0,500,70, а не просто корреляция высокого уровня значимости.В следующей таблице написаны названия коэффициентов корреляции для различных типов шкал.
| Дихотомическая шкала (1/0) | Ранговая (порядковая) шкала | Интервальная и абсолютная шкала | |
| Дихотомическая шкала (1/0) | Коэфициент ассоциации Пирсона, коэффициент четырехклеточной сопряженности Пирсона. | Рангово-бисериальная корреляция. | Бисериальная корреляция |
| Ранговая (порядковая) шкала | Рангово-бисериальная корреляция. | Ранговый коэффициент корреляции Спирмена или Кендалла. | Значения интервальной шкалы переводятся в ранги и используется ранговый коэффициент |
| Интервальная и абсолютная шкала | Бисериальная корреляция | Значения интервальной шкалы переводятся в ранги и используется ранговый коэффициент | Коэффициент корреляции Пирсона (коэффициент линейной корреляции) |
При r=0линейная корреляционная связь отсутствует. При этом групповые средние переменных совпадают с их общими средними, а линии регрессии параллельны осям координат.
Равенство r=0говорит лишь об отсутствии линейной корреляционной зависимости (некоррелированности переменных), но не вообще об отсутствии корреляционной, а тем более, статистической зависимости.
Иногда вывод об отсутствии корреляции важнее наличия сильной корреляции. Нулевая корреляция двух переменных может свидетельствовать о том, что никакого влияния одной переменной на другую не существует, при условии, что мы доверяем результатам измерений.
В SPSS: 11.3.2 Коэффициенты корреляции
До сих пор мы выясняли лишь сам факт существования статистической зависимости между двумя признаками. Далее мы попробуем выяснить, какие заключения можно сделать о силе или слабости этой зависимости, а также о ее виде и направленности. Критерии количественной оценки зависимости между переменными называются коэффициентами корреляции или мерами связанности. Две переменные коррелируют между собой положительно, если между ними существует прямое, однонаправленное соотношение. При однонаправленном соотношении малые значения одной переменной соответствуют малым значениям другой переменной, большие значения — большим. Две переменные коррелируют между собой отрицательно, если между ними существует обратное, разнонаправленное соотношение. При разнонаправленном соотношении малые значения одной переменной соответствуют большим значениям другой переменной и наоборот. Значения коэффициентов корреляции всегда лежат в диапазоне от -1 до +1.
В качестве коэффициента корреляции между переменными, принадлежащими порядковой шкале применяется коэффициент Спирмена, а для переменных, принадлежащих к интервальной шкале — коэффициент корреляции Пирсона (момент произведений). При этом следует учесть, что каждую дихотомическую переменную, то есть переменную, принадлежащую к номинальной шкале и имеющую две категории, можно рассматривать как порядковую.
Для начала мы проверим существует ли корреляция между переменными sex и psyche из файла studium.sav. При этом мы учтем, что дихотомическую переменную sex можно считать порядковой. Выполните следующие действия:
· Выберите в меню команды Analyze (Анализ) Descriptive Statistics (Дескриптивные статистики) Crosstabs... (Таблицы сопряженности)
· Перенесите переменную sex в список строк, а переменную psyche — в список столбцов.
· Щелкните на кнопке Statistics... (Статистика). В диалоге Crosstabs: Statistics установите флажок Correlations (Корреляции). Подтвердите выбор кнопкой Continue.
· В диалоге Crosstabs откажитесь от вывода таблиц, установив флажок Supress tables (Подавлять таблицы). Щелкните на кнопке ОК.
Будут вычислены коэффициенты корреляции Спирмена и Пирсона, а также проведена проверка их значимости:
studopedia.ru
/ Теория. Коэффициент корреляции
5
Коэффициент корреляции - двумерная описательная статистика, количественная мера взаимосвязи (совместной изменчивости) двух переменных.
К настоящему времени разработано великое множество различных коэффициентов корреляции. Однако самые важные меры связи - Пирсона, Спирмена и Кендалла. Их общей особенностью является то, что они отражают взаимосвязь двух признаков, измеренных в количественной шкале - ранговой или метрической.
Вообще говоря, любое эмпирическое исследование сосредоточено на изучении взаимосвязей двух или более переменных.
Если изменение одной переменной на одну единицу всегда приводит к изменению другой переменной на одну и ту же величину, функция является линейной(график ее представляет прямую линию); любая другая связь - нелинейная. Если увеличение одной переменной связано с увеличением другой, то связь - положительная (прямая); если увеличение одной переменной связано с уменьшением другой, то связь - отрицательная (обратная). Если направление изменения одной переменной не меняется с возрастанием (убыванием) другой переменной, то такая функция - монотонная; в противном случае функцию называют немонотонной.
Функциональные связи являются идеализациями. Их особенность заключается в том, что одному значению одной переменной соответствует строго определенное значение другой переменной. Например, такова взаимосвязь двух физических переменных - веса и длины тела (линейная положительная). Однако даже в физических экспериментах эмпирическая взаимосвязь будет отличаться от функциональной связи в силу неучтенных или неизвестных причин: колебаний состава материала, погрешностей измерения и пр.
При изучении взаимосвязи признаков из поля зрения исследователя неизбежно выпадает множество возможных причин изменчивости этих признаков. Результатом является то, что даже существующая в реальности функциональная связь между переменными выступает эмпирически как вероятностная (стохастическая): одному и тому же значению одной переменной соответствует распределение различных значений другой переменной (и наоборот).
Простейшим примером является соотношение роста и веса людей. Эмпирические результаты исследования этих двух признаков покажут, конечно, положительную их взаимосвязь. Но несложно догадаться, что она будет отличаться от строгой, линейной, положительной - идеальной математической функции, даже при всех ухищрениях исследователя по учету стройности или полноты испытуемых. Вряд ли на этом основании кому-то придет в голову отрицать факт наличия строгой функциональной связи между длиной и весом тела.
Итак, функциональная взаимосвязь явлений эмпирически может быть выявлена только как вероятностная связь соответствующих признаков.
Наглядное представление о характере вероятностной связи дает диаграмма рассеивания - график, оси которого соответствуют значениям двух переменных, а каждый испытуемый представляет собой точку. В качестве числовой характеристики вероятностной связи используются коэффициенты корреляции.
Можно ввести три градации величин корреляции по силе связи:
r < 0,3 — слабая связь (менее 10% от общей доли дисперсии);
0,3 < r < 0,7 — умеренная связь (от 10 до 50% от общей доли дисперсии);
r > 0,7 — сильная связь (50% и более от общей доли дисперсии).
Частная корреляция
Часто бывает так, что две переменные коррелируют друг с другом только за счет того, что обе они меняются под влиянием некоторой третьей переменной. То есть, на самом деле связь между соответствующими свойствами этих двух переменных отсутствует, но проявляется в статистической взаимосвязи, или корреляции, под влиянием общей причины третьей переменной).
Таким образом, если корреляция между двумя переменными уменьшается, при фиксируемой третьей случайной величине, то это означает, что их взаимозависимость возникает частично через воздействие этой третьей переменной. Если же частная корреляция равна нулю или очень мала, то можно сделать вывод о том, что их взаимозависимость целиком обусловлена собственным воздействием и никак не связана с третьей переменной.
Также, если частная корреляция больше первоначальной корреляции между двумя переменными, то можно сделать вывод о том, что другие переменные ослабили связь, или "скрыли" корреляцию.
К тому же необходимо помнить о том, что корреляция не есть причинность. Исходя из этого, мы не имеем права безапелляционно говорить о наличии причинной связи: некоторая совершенно отличная от рассматриваемых в анализе переменная может быть источником этой корреляции. Как при обычной корреляции, так и при частных корреляциях предположение о причинности должно всегда иметь собственные внестатистические основания.
Коэффициент корреляции Пирсона
r-Пирсона применяется для изучения взаимосвязи двух метрических переменных, измеренных на одной и той же выборке. Существует множество ситуаций, в которых уместно его применение. Влияет ли интеллект на успеваемость на старших курсах университета? Связан ли размер заработной платы работника с его доброжелательностью к коллегам? Влияет ли настроение школьника на успешность решения сложной арифметической задачи? Для ответа на подобные вопросы исследователь должен измерить два интересующих его показателя у каждого члена выборки.
На величину коэффициента корреляции не влияет то, в каких единицах измерения представлены признаки. Следовательно, любые линейные преобразования признаков (умножение на константу, прибавление константы) не меняют значения коэффициента корреляции. Исключением является умножение одного из признаков на отрицательную константу: коэффициент корреляции меняет свой знак на противоположный.
Корреляция Пирсонаесть мера линейной связи между двумя переменными. Она позволяет определить, насколько пропорциональна изменчивость двух переменных. Если переменные пропорциональны друг другу, то графически связь между ними можно представить в виде прямой линии с положительным (прямая пропорция) или отрицательным (обратная пропорция) наклоном.
На практике связь между двумя переменными, если она есть, является вероятностной и графически выглядит как облако рассеивания эллипсоидной формы. Этот эллипсоид, однако, можно представить (аппроксимировать) в виде прямой линии, или линии регрессии. Линия регрессии - это прямая, построенная методом наименьших квадратов: сумма квадратов расстояний (вычисленных по оси Y) от каждой точки графика рассеивания до прямой является минимальной.
Особое значение для оценки точности предсказания имеет дисперсия оценок зависимой переменной. По сути, дисперсия оценок зависимой переменной Y - это та часть ее полной дисперсии, которая обусловлена влиянием независимой переменной X. Иначе говоря, отношение дисперсии оценок зависимой переменной к ее истинной дисперсии равно квадрату коэффициента корреляции.
Квадрат коэффициента корреляции зависимой и независимой переменных представляет долю дисперсии зависимой переменной, обусловленной влиянием независимой переменной, и называется коэффициентом детерминации. Коэффициент детерминации, таким образом, показывает, в какой степени изменчивость одной переменной обусловлена (детерминирована) влиянием другой переменной.
Коэффициент детерминации обладает важным преимуществом по сравнению с коэффициентом корреляции. Корреляция не является линейной функцией связи между двумя переменными. Поэтому, среднее арифметическое коэффициентов корреляции для нескольких выборок не совпадает с корреляцией, вычисленной сразу для всех испытуемых из этих выборок (т.е. коэффициент корреляции не аддитивен). Напротив, коэффициент детерминации отражает связь линейно и поэтому является аддитивным: допускается его усреднение для нескольких выборок.
Дополнительную информацию о силе связи дает значение коэффициента корреляции в квадрате - коэффициент детерминации: это часть дисперсии одной переменной, которая может быть объяснена влиянием другой переменной. В отличие от коэффициента корреляции коэффициент детерминации линейно возрастает с увеличением силы связи.
Коэффициенты корреляции Спирмена и τ-Кендалла (ранговые корреляции). Если обе переменные, между которыми изучается связь, представлены в порядковой шкале, или одна из них - в порядковой, а другая - в метрической, то применяются ранговые коэффициенты корреляции: Спирмена или τ-Кенделла. И тот, и другой коэффициент требует для своего применения предварительного ранжирования обеих переменных.
Коэффициент ранговой корреляции Спирмена - это непараметрический метод, который используется с целью статистического изучения связи между явлениями. В этом случае определяется фактическая степень параллелизма между двумя количественными рядами изучаемых признаков и дается оценка тесноты установленной связи с помощью количественно выраженного коэффициента.
Если члены группы численностью были ранжированы сначала по переменной x, затем – по переменной y, то корреляцию между переменными x и y можно получить, просто вычислив коэффициент Пирсона для двух рядов рангов. При условии отсутствия связей в рангах (т.е. отсутствия повторяющихся рангов) по той и другой переменной, формула для Пирсона может быть существенно упрощена в вычислительном отношении и преобразована в формулу, известную как Спирмена.
Мощность коэффициента ранговой корреляции Спирмена несколько уступает мощности параметрического коэффициента корреляции.
Коэффицент ранговой корреляции целесообразно применять при наличии небольшого количества наблюдений. Данный метод может быть использован не только для количественно выраженных данных, но также и в случаях, когда регистрируемые значения определяются описательными признаками различной интенсивности.
Коэффициент ранговой корреляции Спирмена при большом количестве одинаковых рангов по одной или обеим сопоставляемым переменным дает огрубленные значения. В идеале оба коррелируемых ряда должны представлять собой две последовательности несовпадающих значений
Альтернативу корреляции Спирмена для рангов представляет корреляция τ-Кендалла. В основе корреляции, предложенной М.Кендаллом, лежит идея о том, что о направлении связи можно судить, попарно сравнивая между собой испытуемых: если у пары испытуемых изменение по x совпадает по направлению с изменением по y, то это свидетельствует о положительной связи, если не совпадает - то об отрицательной связи.
Коэффициенты корреляции были специально разработаны для численного определения силы и направления связи между двумя свойствами, измеренными в числовых шкалах (метрических или ранговых).
Как уже упоминалось, максимальной силе связи соответствуют значения корреляции +1 (строгая прямая или прямо пропорциональная связь) и -1 (строгая обратная или обратно пропорциональная связь), отсутствию связи соответствует корреляция, равная нулю.
Дополнительную информацию о силе связи дает значение коэффициента детерминации: это часть дисперсии одной переменной, которая может быть объяснена влиянием другой переменной.
StudFiles.ru
Тема 12 Корреляционный анализ
Функциональная зависимость и корреляция. Еще Гиппократ в VI в. до н. э. обратил внимание на наличие связи между телосложением и темпераментом людей, между строением тела и предрасположенностью к тем или иным заболеваниям. Определенные виды подобной связи выявлены также в животном и растительном мире. Так, существует зависимость между телосложением и продуктивностью у сельскохозяйственных животных; известна связь между качеством семян и урожайностью культурных растений и т.д. Что же касается подобных зависимостей в экологии, то существуют зависимости между содержанием тяжелых металлов в почве и снежном покрове от их концентрации в атмосферном воздухе и т.п. Поэтому естественно стремление использовать эту закономерность в интересах человека, придать ей более или менее точное количественное выражение.
Как известно, для описания связей между переменными величинами применяют математические понятие функции f, которая ставит в соответствие каждому определенному значению независимой переменной x определенное значение зависимой переменной y, т.е. 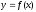 . Такого рода однозначные зависимости между переменными величинамиx и y называют функциональными. Однако такого рода связи в природных объектах встречаются далеко не всегда. Поэтому зависимость между биологическими, а также и экологическими признаками имеет не функциональный, а статистический характер, когда в массе однородных индивидов определенному значению одного признака, рассматриваемого в качестве аргумента, соответствует не одно и то же числовое значение, а целая гамма распределяющихся в вариационный ряд числовых значений другого признака, рассматриваемого в качестве зависимой переменной, или функции. Такого рода зависимость между переменными величинами называется корреляционной или корреляцией..
. Такого рода однозначные зависимости между переменными величинамиx и y называют функциональными. Однако такого рода связи в природных объектах встречаются далеко не всегда. Поэтому зависимость между биологическими, а также и экологическими признаками имеет не функциональный, а статистический характер, когда в массе однородных индивидов определенному значению одного признака, рассматриваемого в качестве аргумента, соответствует не одно и то же числовое значение, а целая гамма распределяющихся в вариационный ряд числовых значений другого признака, рассматриваемого в качестве зависимой переменной, или функции. Такого рода зависимость между переменными величинами называется корреляционной или корреляцией..
Функциональные связи легко обнаружить и измерить на единичных и групповых объектах, однако этого нельзя проделать с корреляционными связями, которые можно изучать только на групповых объектах методами математической статистики. Корреляционная связь между признаками бывает линейной и нелинейной, положительной и отрицательной. Задача корреляционного анализа сводится к установлению направления и формы связи между варьирующими признаками, измерению ее тесноты и, наконец, к проверке достоверности выборочных показателей корреляции.
Зависимость между переменными X и Y можно выразить аналитически (с помощью формул и уравнений) и графически (как геометрическое место точек в системе прямоугольных координат). График корреляционной зависимости строят по уравнению функции  или
или , которая называетсярегрессией. Здесь
, которая называетсярегрессией. Здесь 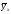 и
и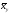 – средние арифметические, найденные при условии, чтоX или Y примут некоторые значения x или y. Эти средние называются условными.
– средние арифметические, найденные при условии, чтоX или Y примут некоторые значения x или y. Эти средние называются условными.
11.1. Параметрические показатели связи
Коэффициент корреляции. Сопряженность между переменными величинами x и y можно установить, сопоставляя числовые значения одной из них с соответствующими значениями другой. Если при увеличении одной переменной увеличивается другая, это указывает на положительную связь между этими величинами, и наоборот, когда увеличение одной переменной сопровождается уменьшением значения другой, это указывает на отрицательную связь.
Для характеристики связи, ее направления и степени сопряженности переменных применяют следующие показатели:
-
линейной зависимость – коэффициент корреляции;
-
нелинейный – корреляционной отношение.
Для определения эмпирического коэффициента корреляции используют следующую формулу:
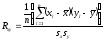 . (1)
. (1)
Здесь sx и sy – средние квадратические отклонения.
Коэффициент корреляции можно вычислить, не прибегая к расчету средних квадратических отклонений, что упрощает вычислительную работу, по следующей аналогичной формуле:
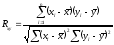 . (2)
. (2)
Коэффициент корреляции – безразмерное число, лежащее в пределах от –1 до +1. При независимом варьировании признаков, когда связь между ними полностью отсутствует, 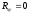 . Чем сильнее сопряженность между признаками, тем выше значение коэффициента корреляции. Следовательно, при
. Чем сильнее сопряженность между признаками, тем выше значение коэффициента корреляции. Следовательно, при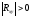 этот показатель характеризует не только наличие, но и степень сопряженности между признаками. При положительной или прямой связи, когда большим значениям одного признака соответствуют большие же значения другого, коэффициент корреляции имеет положительный знак и находится в пределах от 0 до +1, при отрицательной или обратной связи, когда большим значениям одного признака соответствуют меньшие значения другого, коэффициент корреляции сопровождается отрицательным знаком и находится в пределах от 0 до –1.
этот показатель характеризует не только наличие, но и степень сопряженности между признаками. При положительной или прямой связи, когда большим значениям одного признака соответствуют большие же значения другого, коэффициент корреляции имеет положительный знак и находится в пределах от 0 до +1, при отрицательной или обратной связи, когда большим значениям одного признака соответствуют меньшие значения другого, коэффициент корреляции сопровождается отрицательным знаком и находится в пределах от 0 до –1.
Коэффициент корреляции нашел широкое применение в практике, но он не является универсальным показателем корреляционных связей, так как способен характеризовать только линейные связи, т.е. выражаемые уравнением линейной регрессии (см. тему 12). При наличии нелинейной зависимости между варьирующими признаками применяют другие показатели связи, рассмотренных ниже.
Вычисление коэффициента корреляции. Это вычисление производят разными способами и по-разному в зависимости от числа наблюдений (объема выборки). Рассмотрим отдельно специфику вычисления коэффициента корреляции при наличии малочисленных выборок и выборок большого объема.
Малые выборки. При наличии малочисленных выборок коэффициент корреляции вычисляют непосредственно по значениям сопряженных признаков, без предварительной группировки выборочных данных в вариационные ряды. Для этого служат приведенные выше формулы (1) и (2). Более удобными, особенно при наличии многозначных и дробных чисел, которыми выражаются отклонения вариант хi и yi от средних 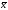 и
и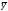 , служат следующие рабочие формулы:
, служат следующие рабочие формулы:
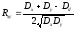 , (3)
, (3)
где 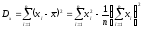 ;
;
 ;
;
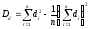 .
.
Здесь xi и yi – парные варианты сопряженных признаков x и y; 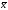 и
и 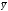 –средние арифметические;
–средние арифметические;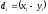 – разность между парными вариантами сопряженных признаковx и y; n – общее число парных наблюдений, или объем выборочной совокупности.
– разность между парными вариантами сопряженных признаковx и y; n – общее число парных наблюдений, или объем выборочной совокупности.
Эмпирический коэффициент корреляции, как и любой другой выборочный показатель, служит оценкой своего генерального параметра ρ и как величина случайная сопровождается ошибкой:
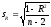 . (4)
. (4)
Отношение выборочного коэффициента корреляции к своей ошибке служит критерием для проверки нулевой гипотезы – предположения о том, что в генеральной совокупности этот параметр равен нулю, т.е. 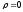 . Нулевую гипотезу отвергают на принятом уровне значимостиα, если
. Нулевую гипотезу отвергают на принятом уровне значимостиα, если
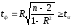 . (5)
. (5)
Значения критических точек tstдля разных уровней значимости α и чисел степеней свободы 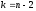 приведены в табл.1 Приложений.
приведены в табл.1 Приложений.
Установлено, что при обработке малочисленных выборок (особенно когда n < 30) расчет коэффициента корреляции по формулам (1) – (3) дает несколько заниженные оценки генерального параметра ρ, т.е. необходимо внести следующую поправку:
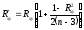 . (6)
. (6)
z-преобразование Фишера. Правильное применение коэффициента корреляции предполагает нормальное распределение двумерной совокупности сопряженных значений случайных величин x и y. Из математической статистики известно, что при наличии значительной корреляции между переменными величинами, т.е. когда Rxy> 0,5 выборочное распределение коэффициента корреляции для большего числа малых выборок, взятых из нормально распределяющейся генеральной совокупности, значительно отклоняются от нормальной кривой.
Учитывая это обстоятельство, Р. Фишер нашел более точный способ оценки генерального параметра по значению выборочного коэффициента корреляции. Этот способ сводится к замене Rxy преобразованной величиной z, которая связана с эмпирическим коэффициентом корреляции, следующим образом:
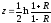 . (7)
. (7)
Распределение величины z является почти неизменным по форме, так как мало зависит от объема выборки и от значения коэффициента корреляции в генеральной совокупности, и приближается к нормальному распределению.
Критерием достоверности показателя z является следующее отношение:
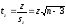 . (7)
. (7)
Нулевая гипотеза отвергается на принятом уровне значимости α и числе степеней свободы  . Значения критических точекtstприведены в табл.1 Приложений.
. Значения критических точекtstприведены в табл.1 Приложений.
Применение z-преобразования позволяет с большей уверенностью оценивать статистическую значимость выборочного коэффициента корреляции, а также и разность между эмпирическими коэффициентами 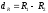 , когда в этом возникает необходимость.
, когда в этом возникает необходимость.
Минимальный объем выборки для точной оценки коэффициента корреляции. Можно рассчитать объем выборки для заданного значения коэффициента корреляции, который был бы достаточен для опровержения нулевой гипотезы (если корреляция между признаками Y и X действительно существует). Для этого служит следующая формула:
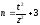 , (8)
, (8)
где n – искомый объем выборки; t – величина, заданная по принятому уровню значимости (лучше для α = 1%); z – преобразованный эмпирический коэффициент корреляции.
Большие выборки. При наличии многочисленных исходных данных их приходится группировать в вариационные ряды и, построив корреляционную решетку, разность по ее клеткам (ячейкам) общие частоты сопряженных рядов. Корреляционная решетка образуется пересечением строк и столбцов, число которых равно числу групп или классов коррелируемых рядов. Классы располагаются в верхней строке и в первой (слева) столбце корреляционной таблицы, а общие частоты, обозначаемые символом fxy, – в клетках корреляционной решетки, составляющей основную часть корреляционной таблицы.
Классы, помещенные в верхней строке таблицы, обычно располагаются слева направо в возрастающем порядке, а в первом столбце таблицы – сверху вниз в убывающем порядке. При таком расположении классов вариационных рядов их общие частоты (при наличии положительной связи между признаками Y и X) будут распределяться по клеткам решетки в виде эллипса по диагонали от нижнего левого угла к верхнему правому углу решетки или (при наличии отрицательной связи между признаками) в направлении от верхнего левого угла к нижнему правому углу решетки. Если же частоты fxy распределяются по клеткам корреляционной решетки более или менее равномерно, не образуя фигуры эллипса, это будет указывать на отсутствие корреляции между признаками.
Распределение частот fxy по клеткам корреляционной решетки дает лишь общее представление о наличии или отсутствии связи между признаками. Судить о тесноте или менее точно лишь по значению и знаку коэффициента корреляции. При вычислении коэффициента корреляции с предварительной группировки выборочных данных в интервальные вариационные ряды не следует брать слишком широкие классовые интервалы. Грубая группировка гораздо сильнее сказывается на значении коэффициента корреляции, чем это имеет место при вычислении средних величин и показателей вариации.
Напомним, что величина классового интервала определяется по формуле
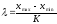 , (9)
, (9)
где xmax, xmin– максимальная и минимальная варианты совокупности; К – число классов, на которые следует разбить вариацию признака. Опыт показал, что в области корреляционного анализа величину К можно поставить в зависимость от объема выборки примерно следующим образом (табл.1).
Таблица 1
|
Объем выборки |
Значение К |
|
50 ≥ n > 30 |
|
|
100 ≥ n > 50 |
|
|
200 ≥ n > 100 |
|
|
300 ≥ n > 200 |
|
Как и другие статистические характеристики, вычисляемые с предварительной группировкой исходных данных в вариационные ряды, коэффициент корреляции определяют разными способами, дающими совершенно идентичные результаты.
Способ произведений. Коэффициент корреляции можно вычислить используя основные формулы (1) или (2), внеся в них поправку на повторяемость вариант в димерной совокупности. При этом, упрощая символику, отклонения вариант от их средних обозначим через а, т.е. 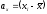 и
и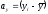 . Тогда формула (2) с учетом повторяемости отклонений примет следующее выражение:
. Тогда формула (2) с учетом повторяемости отклонений примет следующее выражение:
 . (10)
. (10)
Достоверность этого показателя оценивается с помощью критерия Стьюдента, который представляет отношение выборочного коэффициента корреляции к своей ошибке, определяемой по формуле
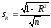 . (11)
. (11)
Отсюда 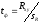 и если эта величина превышает стандартное значение критерия Стьюдентаtst для степени свободы
и если эта величина превышает стандартное значение критерия Стьюдентаtst для степени свободы 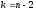 и уровне значимостиα (см. Таблицу 2 Приложений), то нулевую гипотезу отвергают.
и уровне значимостиα (см. Таблицу 2 Приложений), то нулевую гипотезу отвергают.
Способ условных средних. При вычислении коэффициента корреляции отклонения вариант (“классов”) можно находить не только от средних арифметических 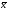 и
и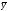 , но и от условных средних Ах и Ay. При этом способе в числитель формулы (2) вносят поправку и формула приобретает следующий вид:
, но и от условных средних Ах и Ay. При этом способе в числитель формулы (2) вносят поправку и формула приобретает следующий вид:
 , (12)
, (12)
где fxy – частоты классов одного и другого рядов распределения; 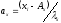 и
и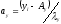 , т.е. отклонения классов от условных средних, отнесенные к величине классовых интерваловλ; n – общее число парных наблюдений, или объем выборки;
, т.е. отклонения классов от условных средних, отнесенные к величине классовых интерваловλ; n – общее число парных наблюдений, или объем выборки; 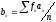 и
и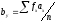 – условные моменты первого порядка, гдеfx – частоты ряда Х, аfy – частоты ряда Y; sxи sy – средние квадратические отклонения рядов Xи Y, вычисляемые по формуле
– условные моменты первого порядка, гдеfx – частоты ряда Х, аfy – частоты ряда Y; sxи sy – средние квадратические отклонения рядов Xи Y, вычисляемые по формуле 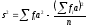 .
.
Способ условных средних имеет преимущество перед способом произведений, так как позволяет избегать операции с дробными числами и придавать один и тот же (положительный) знак отклонениям axи ay, что упрощает технику вычислительной работы, особенно при наличии многозначных чисел.
Оценка разности между коэффициентами корреляции. При сравнении коэффициентов корреляции двух независимых выборок нулевая гипотеза сводится к предположению о том, что в генеральной совокупности разница между этими показателями равна нулю. Иными словами, следует исходить из предположения, что разница, наблюдаемая между сравниваемыми эмпирическими коэффициентами корреляции, возникла случайно.
Для проверки нулевой гипотезы служит t-критерий Стьюдента, т.е. отношение разности между эмпирическими коэффициентами корреляции R1 и R2 к своей статистической ошибке, определяемой по формуле:
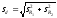 , (13)
, (13)
где sR1 и sR2 – ошибки сравниваемых коэффициентов корреляции.
Нулевая гипотеза опровергается при условии, что 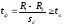 для принятого уровне значимостиα и числе степеней свободы
для принятого уровне значимостиα и числе степеней свободы 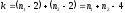 .
.
Известно, что более точную оценку достоверности коэффициента корреляции получают при переводе Rxy в число z. Не является исключением и оценка разности между выборочными коэффициентами корреляции R1 и R2, особенно в тех случаях, когда последние вычислены на выборках сравнительно небольшого объема (n < 100) и по своему абсолютному значению значительно превышают 0,50.
Разность 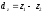 оценивают с помощью t-критерия Стьюдента, который строят по отношению этой разности к своей ошибке, вычисляемой по формуле
оценивают с помощью t-критерия Стьюдента, который строят по отношению этой разности к своей ошибке, вычисляемой по формуле
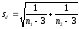 . (14)
. (14)
Нулевую гипотезу отвергают, если 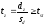 для
для и принятого уровня значимостиα.
и принятого уровня значимостиα.
Корреляционное отношение. Для измерения нелинейной зависимости между переменными x и y используют показатель, который называют корреляционным отношением, который описывает связь двусторонне. Конструкция корреляционного отношения предполагает сопоставление двух видов вариации: изменчивости отдельных наблюдений по отношению к частным средним и вариации самих частных средних по сравнению с общей средней величиной. Чем меньшую часть составит первый компонент по отношению ко второму, тем теснота связи окажется большей. В пределе, когда никакой вариации отдельных значений признака возле частных средних не будет наблюдаться, теснота связи окажется предельно большой. Аналогичным образом, при отсутствии изменчивости частных средних теснота связи окажется минимальной. Так как это соотношение вариации может быть рассмотрено для каждого из двух признаков, получается два показателя тесноты связи – hyx и hxy. Корреляционное отношение является величиной относительной и может принимать значения от 0 до 1. При этом коэффициенты корреляционного отношения обычно не равны друг другу, т.е. 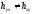 . Равенство между этими показателями осуществимо только при строго линейной зависимости между признаками. Корреляционное отношение является универсальным показателем: оно позволяет характеризировать любую форму корреляционной связи – и линейную, и нелинейную.
. Равенство между этими показателями осуществимо только при строго линейной зависимости между признаками. Корреляционное отношение является универсальным показателем: оно позволяет характеризировать любую форму корреляционной связи – и линейную, и нелинейную.
Коэффициенты корреляционного отношения hyx и hxy определяют рассмотренными выше способами, т.е. способом произведений и способом условных средних.
Способ произведений. Коэффициенты корреляционного отношения hyx и hxy определяют по следующим формулам:
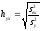 и
и 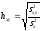 , (15)
, (15)
где  и
и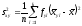 – групповые дисперсии,
– групповые дисперсии,
а 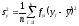 и
и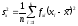 – общие дисперсии.
– общие дисперсии.
Здесь 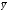 и
и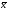 – общие средние арифметические, а
– общие средние арифметические, а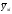 и
и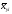 – групповые средние арифметические;fyi – частоты ряда Y, а fxi– частоты ряда X; k – количество классов; n – количество варьирующих признаков.
– групповые средние арифметические;fyi – частоты ряда Y, а fxi– частоты ряда X; k – количество классов; n – количество варьирующих признаков.
Рабочие формулы для расчета коэффициентов корреляционного отношения следующие:
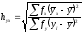 и
и 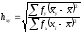 . (16)
. (16)
Способ условных средних. Определяя коэффициенты корреляционного отношения по формулам (15), отклонения классовых вариант xi и yi можно брать не только от средних арифметических и, но и от условных средних Ах и Ay. В таких случаях групповые и общие девиаты рассчитываются по формулам 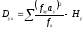 и
и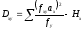 , а также,
, а также,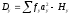 и
и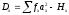 , где
, где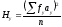 и
и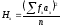 .
.
В развернутом виде формулы (15) выглядят следующим образом:
 ;
;
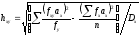 . (17)
. (17)
В этих формулах 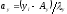 и
и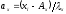 – отклонения классов от условных средних, сокращенные на величину классовых интервалов; значенияay и axвыражаются числами натурального ряда: 0, 1, 2, 3, 4, … .Остальные символы объяснены выше.
– отклонения классов от условных средних, сокращенные на величину классовых интервалов; значенияay и axвыражаются числами натурального ряда: 0, 1, 2, 3, 4, … .Остальные символы объяснены выше.
Сравнивая способ произведений со способом условных средних, нельзя не заметить преимущество первого способа, особенно в тех случаях, когда приходится иметь дело с многозначными числами. Как и другие выборочные показатели, корреляционное отношение является оценкой своего генерального параметра и, как величина случайная, сопровождается ошибкой, определяемой по формуле
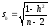 . (12)
. (12)
Достоверность оценки корреляционного отношения можно проверить по t-критерию Стьюдента. H0-гипотеза исходит из предположения, что генеральный параметр равен нулю, т.е. должно выполнятся следующее условие:
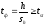 (13)
(13)
для числа степеней свободы и уровня значимостиα.
Коэффициент детерминации. Для истолкования значений, принимаемых показателями тесноты корреляционной связи, используют коэффициенты детерминации, которые показывают, какая доля вариации одного признака зависит от варьирования другого признака. При наличии линейной связи коэффициентом детерминации служит квадрат коэффициента корреляции R2xy, а при нелинейной зависимости между признаками y и x – квадрат корреляционного отношения h2yx. Коэффициенты детерминации дают основание построить следующую примерную шкалу, позволяющую судить о тесноте связи между признаками: при  связь считается средней;
связь считается средней;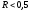 указывает на слабую связь и лишь при
указывает на слабую связь и лишь при можно судить о сильной связи, когда около 50 % вариации признакаY зависит от вариации признака X.
можно судить о сильной связи, когда около 50 % вариации признакаY зависит от вариации признака X.
Оценка формы связи. При строго линейной зависимости между переменными величинами y и x осуществляется равенство 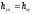 . В таких случаях коэффициенты корреляционного отношения совпадают со значением коэффициента корреляции. Совпадут при этом по своему значению и коэффициенты детерминации, т.е.
. В таких случаях коэффициенты корреляционного отношения совпадают со значением коэффициента корреляции. Совпадут при этом по своему значению и коэффициенты детерминации, т.е.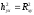 . Следовательно, по разности между этими величинами можно судить о форме корреляционной зависимости между переменнымиy и x:
. Следовательно, по разности между этими величинами можно судить о форме корреляционной зависимости между переменнымиy и x:
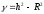 . (14)
. (14)
Очевидно, что при линейной связи между переменными y и x показатель γ будет равен нулю; если же связь между переменными y и x нелинейная, γ > 0.
Показатель γ является оценкой генерального параметра и, как величина случайная, нуждается в проверке достоверности. При этом исходят из предположения о том, что связь между величинами y и x линейна (нулевая гипотеза). Проверить эту гипотезу позволяет F-критерий Фишера:
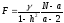 , (15)
, (15)
где a – численность групп, или классов вариационного ряда; N – объем выборки. Нулевую гипотезу отвергают, если  для
для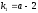 (находят по горизонтали табл.2 Приложений),
(находят по горизонтали табл.2 Приложений),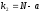 (находят в первом столбце той же таблицы) и принятого уровня значимостиα.
(находят в первом столбце той же таблицы) и принятого уровня значимостиα.
StudFiles.ru
Определение значимости корреляции
Классификации коэффициентов корреляции
Коэффициенты корреляции характеризуются силой и значимостью.
Классификация коэффициентов корреляции по силе.
| сильная | r > 0,70 |
| средняя | 0,50 < r < 0,69 |
| умеренная | 0,30 < r < 0,49 |
| слабая | 0,20 < r < 0,29 |
| очень слабая | r < 0,19 |
Классификация коэффициентов корреляции по значимости.
| Высокозначимая корреляция | r соответствует уровню статистической значимости p ≤ 0,01 |
| Значимая корреляция | r соответствует уровню статистической значимости p ≤ 0,05 |
| Незначимая корреляция | r не достигает уровня статистической значимости p>0,1 |
Не следует путать 2 этих классификации, так как они определяют разные характеристики. Сильная корреляция может оказаться случайной и, стало быть, недостоверной. Особенно часто это случается в выборке с малым объемом. А в большой выборке даже слабая корреляция может оказаться высокозначимой.
После вычисления коэффициента корреляции необходимо выдвинуть статистические гипотезы:
Н0: показатель корреляции значимо не отличается от нуля (является случайным).
Н1: показатель корреляции значимо отличается от нуля (является неслучайным).
Проверка гипотез осуществляется сравнением полученных эмпирических коэффициентов с табличными критическими значениями. Если эмпирическое значение достигает критического или превышает его, то нулевая гипотеза отвергается: rэмп ≥ rкр  Но, Þ Н1 . В таких случаях делают вывод, что обнаружена достоверность различий.
Но, Þ Н1 . В таких случаях делают вывод, что обнаружена достоверность различий.
Если эмпирическое значение не превышает критического, то нулевая гипотеза не отвергается: rэмп < rкр Þ Н0 . В таких случаях делают вывод, что достоверность различий не установлена.
studopedia.ru
/ Статистика / Корреляция
Вычисление матрицы парных коэффициентов
корреляции
Для расчета матрицы парных коэффициентов корреляции следует вызвать меню Корреляционные матрицы модуля Основные статистики.

Рис. 1 Панель модуля основные статистики
Основные этапы проведения корреляционного анализа в системе SТАТІSТІСА рассмотрим на данных примера (см. рис. 2). Исходные данные представляют собой результаты наблюдений за деятельностью 23 предприятий одной из отрас-лей промышленности.
Рис.2 Исходные данные
Графы таблицы содержат следующие показатели:
РЕНТАБЕЛ — рентабельность, %;
ДОЛЯ РАБ — удельный вес рабочих в составе ППП, ед.;
ФОНДООТД — фондоотдача, ед.;
ОСНФОНДЫ — среднегодовая стоимость основных производственных фондов, млн руб.;
НЕПРРАСХ — непроизводственные расходы, тыс. руб. Требуется исследовать зависимость рентабельности от дрУ'
гих показателей.
Предположим, что рассматриваемые признаки в генераль-ной совокупности подчиняются нормальному закону распределения, а данные наблюдений представляют собой выборку из совокупности.
Вычислим парные коэффициенты корреляции между всеми переменными. После выбора строки Корреляционные матрицы на экране появится диалоговое окно Корреляции Пирсона. Название обусловлено тем, что впервые этот коэффициент был Пирсоном, Эджвортом и Велдоном.
Выберем переменные для анализа. Для этого в диалоговом окне имеются две кнопки: Квадр. матрица (один список) и Прямоуг. матрица (два списка).
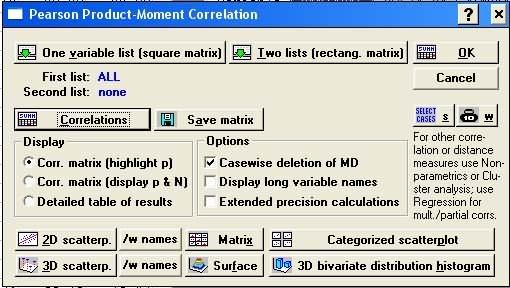
Рис. 3 Диалоговое окно корреляционного анализа
Первая кнопка предназначена для вычисления матрицы обыч. ного симметричного вида с парными коэффициентами корреля-ции всех сочетаний переменных. Если при анализе используют-ся все показатели, то в диалоговом окне выбора переменных можно нажать кнопку Выбрать все. (Если переменные идут не подряд, их можно выбрать щелчком мыши с одновременно нажатой клавишей Ctrl)

Рис. 4
Если нажать кнопку Подроб. диалогового окна, то для каж-дой переменной будут отображаться длинные имена. Щелкнув эту кнопку еще раз (она примет название Кратко), получим короткие имена.
Кнопка Информация открывает окно для выбранной пере-менной, в котором можно просмотреть ее характеристики: длинное имя, формат отображения, отсортированный список значе-ний, описательные статистики (количество значений, среднее, стандартное отклонение).
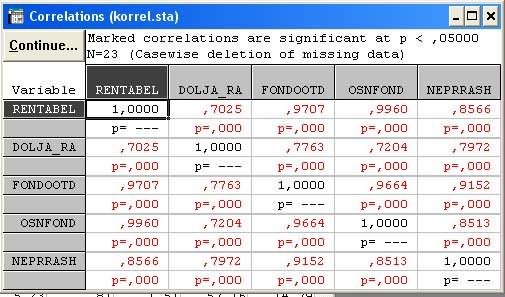
После выбора переменных нажмем ОК или кнопку Корреляции диалогового окна Корреляции Пирсона. На экране появится рассчитанная корреляционная матрица.
Значимые коэффициенты корреляции на экране выделяются красным цветом.
В нашем примере показатель рентабельности оказался наиболее связан с показателями фондоотдача (связь прямая) и производственные расходы (обратная связь, предполагающая реньшение V с увеличением X). Но насколько тесно взаимоязаны признаки? Тесной считается связь при значениях коэфциента по модулю больше чем 0.7 и слабой — меньше 0.3. таким образом, при дальнейшем построении уравнения регрессии следует ограничиться показателями «Фондоотдача» и «Непроизводственные расходы» как наиболее информативными.
Однако в нашем примере наблюдается явление мультиколшрности, когда существует связь между самими независимыми переменными (парный коэффициент корреляции по модулю больше чем 0.8).
Опция прямоугольная матрица (два списка переменных) открывает диалоговое окно выбора двух списков переменных. Поместим как на рисунке

Рис. 6
В результате получаем прямоугольную корреляционную матрицу, содержащую лишь коэффициенты корреляции с зависимой переменной.
Если установлена опция Корр. Матрицу (выдел. значимые),то после нажатия кнопкиКорреляция будет построена матрица с коэф., выделенными на уровне значимостир.
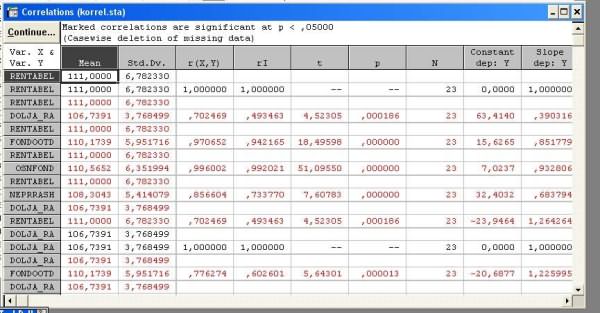
Если выбрана опция Подробная таблица результатов, то, на-жав кнопку Корреляции, получим таблицу, которая содержит не только коэффициенты корреляции, но также средние, стан-дартные отклонения, коэффициенты уравнения регрессии, сво-бодный член в уравнении регрессии и другие статистики
Когда переменные имеют небольшую относительную вариацию (отношение стандартного отклонения к среднему меньше чем 0.0000000000001), требуется более высокая степень оценки. Ее можно задать, пометив галочкой опцию Вычисления с повы-шенной точностью диалогового окна Корреляции Пирсона.
Режим работы с пропущенными данными определяется оп-цией Построчное удаление ПД. Если ее выбрать, то SТАТІSТІСА проигнорирует все наблюдения, имеющие пропуски. В против-ном случае производится их попарное удаление.
Помеченный галочкой режим Отображать длинные имена переменных приведет к получению таблицы с длинными имена-ми переменных.
Графическое изображение корреляционных зависимостей
Диалоговое окно Корреляции Пирсона содержит ряд кнопок для получения графического изображения корреляционных зависимостей.
Опция 2М рассеяния строит последовательность диаграмм Рассеяния для каждой выбранной переменной. Окно для их выбора идентично рисунку 6. Слева следует указать висимые переменные, справа независимую — РЕНТАБЕЛ. Нажав ОК, получим график, на котором будет изображена одогнанная регрессионная прямая и доверительные границы рогноза.
Линейный коэффициент корреляции дает наиболее объективную оценку тесноты связи, если расположение точек в системе координат напоминает прямую линию или вытянутый эллипс, если же точки расположены в виде кривой, то коэффициент орреляции дает заниженную оценку.
На основе графика мы можем еще раз подтвердить взаимосвязь между показателями рентабельности и фондоотдачи, как данные наблюдений расположились в виде наклонного эллипса. Надо сказать, что связь считается тем теснее, чем бли-же точки к главной оси эллипса.
В нашем примере изменение показателя фондоотдачи на единицу приведет к изменению рентабельности на 5.7376%.
Посмотрим влияние показателя непроизводственных расходов на значение рентабельности. Для этого построим аналогичный график
Анализируемые данные уже меньше напоминают по своей форме эллипс, да и коэффициент корреляции несколько ниже. Найденное значение коэффициента регрессии показывает, что при увеличении непроизводственных расходов на 1 тысячу рублей рентабельность уменьшается на 0.7017%.
Следует заметить, что построение множественной регрессии (рассмотренное в последующих главах), когда уравнение со-держит одновременно оба признака, приводит к другим значе-ниям коэффициентов регрессии, что объясняется взаимодействи-ем объясняющих переменных между собой.
При использовании кнопки С именами точки на диаграмме рассеяния приобретут соответствующие им номера или имена, если они предварительно заданы.
Следующая опция с указанием графика Матричный строит атрицу диаграмм рассеяния для выбранных переменных.
ждый графический элемент этой матрицы содержит корреля-яонные поля, образуемые соответствующими переменными с
поженной на них линией регрессии.
При анализе матрицы диаграмм рассеяния следует обратить внимание на те графики, линии регрессии которых имеют суще-ственный наклон к оси X, что позволяет предположить суще-ствование взаимозависимости между соответствующими при-знаками.
Опция ЗМ рассеяния строит трехмерное корреляционное поле для выбранных переменных. Если использована кнопка С именами, точки на диаграмме рассеяния будут помечены номерами или именами соответствующих наблюдений, если они их имеют.
Графическая опция Поверхность строит ЗМ диаграмму рассеяния для выбранной тройки переменных вместе с подогнанной поверхностью второго порядка.
Опция Категор. диаграммы рассеяния в свою очередь строит каскад корреляционных полей для выбранных показателей.
После нажатия соответствующей кнопки программа попросит пользователя составить два их набора из отобранных ранее с помощью кнопки Переменные. Затем на экране появится новое
окно запроса для задания группирующей переменной, на основе которой будут классифицированы все имеющиеся наблюдения.
Результатом является построение корреляционных полей в резе групп наблюдений для каждой пары переменных, отне-яных к разным спискам
3.4. Расчет частных и множественных коэффициентов корреляции
Для расчета частных и множественных коэффициентов кор. реляции вызовем модуль Множественная регрессия, используя кнопку переключателя модулей. На экране появится следующее диалоговое окно:
Нажав кнопку Переменные, выберем переменные для анализа: слева зависимую — рентабельность, а справа независимые — фондоотдача и непроизводственные расходы. Остальные переменные не будут участвовать в дальнейшем анализе — на основе проведения корреляционного анализа они признаны не-информативными для регрессионной модели.
В поле Файл ввода в качестве входных данных предлагаются обычные исходные данные, представляющие собой таблицу с переменными и наблюдениями, или корреляционная матрица. Корреляционную матрицу можно предварительно создать в самом модуле Множественная регрессия или вычислить с помо-щью опции Быстрые основные статистики.
При работе с файлом исходных данных можно задать ре-жим работы с пропусками:
-
Построчное удаление. При выборе этой опции в анализе используются только те наблюдения, которые не имеют пропущенных значений во всех выбранных переменных.
-
Замена средним. Пропущенные значения в каждой переменной заменяются средним, вычисленным по имеющимся комплектным наблюдениям.
-
Попарное удаление пропущенных данных. Если выбрана эта опция, то при вычислении парных корреляций удаля-ются наблюдения, имеющие пропущенные значения в соответствующих парах переменных.
В поле Тип регрессии пользователь может выбрать стандартную или фиксированную нелинейную регрессию. По умолчачанию выбирается стандартный анализ множественной регрессии, при котором вычисляется стандартная корреляционная матрица всех выбранных переменных.
Режим Фиксированная нелинейная регрессия позволяет осуществить различные преобразования независимых переменных. Опция Провести анализ по умолчанию использует установки, соответствующие определению стандартной регрессионной рдели, включающей свободный член. Если эта опция отменена, то при щелчке мышью по кнопке ОК стартовой панели эется диалоговое окно Определение модели, в котором вы эжете выбрать как тип регрессионного анализа (например, пошаговый, гребневый и др.), так и другие опции.
Установив флажок строки опции Показывать описательные описательные, корр. матрицы и щелкнув ОК, получим диалоговое окно со статистическими характеристиками данных.
В нем вы можете просмотреть подробные описательные статистики (в том числе количество наблюдений, по которым был вычислен коэффициент корреляции для каждой пары переменных). Чтобы продолжить анализ и открыть диалоговое окно Определители модели, нажмите ОК.
Если анализируемые показатели имеют чрезвычайно малую относительную дисперсию, вычисляемую как общая дисперсия, деленная на среднее, то следует установить флажок около опции Вычисления с повышенной точностью для получения более точных значений элементов корреляционной матрицы.
Установив все необходимые параметры в диалоговом окне Множественная регрессия, нажмем ОК и получим результаты требуемых вычислений.
По данным нашего примера множественный коэффициент корреляции получился равным 0.61357990 и соответственно коэффициент детерминации — 0.37648029. Таким образом, лишь 37,6% дисперсии показателя «рентабельность» объясняется из-менением показателей «фондоотдачи» и «непроизводственных расходов». Такое низкое значение свидетельствует о недостаточ-ном числе факторов, введенных в модель. Попробуем изменить количество независимых переменных, дополнив список пере-менной «Основные фонды» (введение в модель показателя «доля рабочих в ППП» приводит к мультиколлениарности, что явля-ется недопустимым). Коэффициент детерминации несколько повысился, но не настолько, чтобы существенно улучшить результаты — его значение составило около 41%. Очевидно, наша дача требует дополнительных исследований по выявлению факторов, влияющих на рентабельность.
Значимость множественного коэффициента корреляции про-ряется по таблице Ф-критерия Фишера. Гипотеза о его значимости отвергается, если значение вероятности отклонения превышает заданный уровень (чаще всего берут а=0.1, 0.05; 0.01 0.001). В нашем примере р=0.008882 < 0.05, что свидетельствует о значимости коэффициента.
Таблица результатов содержит следующие графы:
-
Коэффициент Бета (в) — стандартизованный коэффициент регрессии ддя соответствующей переменной;
-
Частная корреляция — частные коэффициенты корреля-ции между соответствующей переменной и зависимой, при фиксировании влияния остальных, входящих в модель.
Частный коэффициент корреляции между рентабельностью и фондоотдачей в нашем примере равен 0.459899. Это означает, после ввода в модель показателя непроизводственных рас-эв влияние фондоотдачи на рентабельность несколько сни-пось — с 0.49 (значение парного коэффициента корреляции) 0.46. Аналогичный коэффициент для показателя непроизвод-аенных расходов также снизился — с 0.46 (значение парного коэффициента корреляции) до 0.42 (берут значение по модулю), характеризует изменение связи с зависимой переменной че ввода в модель показателя фондоотдачи.
-
Получастная корреляция — корреляция между нескорректированной зависимой переменной и соответствующей не-зависимой с учетом влияния остальных, включенных в модель.
-
Толерантность (определяется как 1 минус квадрат множественной корреляции между соответствующей переменной и всеми независимыми переменными в уравнении регрес- сии).
-
Коэффициент детерминации — квадрат коэффициента множественной корреляции между соответствующей независимой переменной и всеми остальными переменными, входящими в регрессионное уравнение.
-
1-значения — расчетное значение критерия Стьюдента для проверки гипотезы о значимости частного коэффициента корреляции с указанным (в скобках) числом степеней свободы.
-
р-уровень! — вероятность отклонения гипотезы о значимости частного коэффициента корреляции.
В нашем случае полученное значение р для первого коэффициента (0.031277) меньше выбранного =0.05. Значение вто-рого коэффициента его несколько превышает (0.050676), что говорит о его незначимости на этом уровне. Но он значим, например, при =0.1 (в десяти случаях из ста гипотеза окажется все-таки неверна).
StudFiles.ru
Читайте также
 Аутентичность значение слова
Аутентичность значение слова Чувак значение слова с еврейского
Чувак значение слова с еврейского- 7 Треф значение
 Славянские имена мальчиков и их значение
Славянские имена мальчиков и их значение Барыга значение слова википедия
Барыга значение слова википедия Амбициозный значение слова
Амбициозный значение слова Старинные русские слова и их значение
Старинные русские слова и их значение Амир значение имени характер и судьба
Амир значение имени характер и судьба Балда значение слова
Балда значение слова Бит может принимать значения
Бит может принимать значения Тимур значение имени характер
Тимур значение имени характер Города федерального значения россии список
Города федерального значения россии список
 Аутентичность значение слова
Аутентичность значение слова Чувак значение слова с еврейского
Чувак значение слова с еврейского Славянские имена мальчиков и их значение
Славянские имена мальчиков и их значение Барыга значение слова википедия
Барыга значение слова википедия Амбициозный значение слова
Амбициозный значение слова Старинные русские слова и их значение
Старинные русские слова и их значение Амир значение имени характер и судьба
Амир значение имени характер и судьба Балда значение слова
Балда значение слова Бит может принимать значения
Бит может принимать значения Тимур значение имени характер
Тимур значение имени характер Города федерального значения россии список
Города федерального значения россии список