Поисковые системы это:
Поисковые системыПоиско́вая систе́ма — веб-сайт, предоставляющий возможность поиска информации в Интернете. Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлы на ftp-серверах, товары в интернет-магазинах, а также информацию в .
Как правило, основной частью поисковой системы является поиско́вая маши́на (поиско́вый движо́к) — комплекс программ, обеспечивающий функциональность поисковой системы. Основными критериями качества работы поисковой машины являются релевантность(степень соответствия запроса и найденного, то есть уместность результата), полнота базы, учёт морфологии языка. Индексация информации осуществляется специальными поисковыми роботами. В последнее время появился новый тип поисковых движков, основанных на технологии
Улучшение поиска — это одна из приоритетных задач сегодняшнего Интернета (см. про основные проблемы в работе поисковых систем в Глубокая паутина).
По данным компании Net Applications[1] в декабре 2007 года рыночная доля распределялась:
- Yahoo — 12,46 %
- Microsoft Live Search — 2,57 %
- Ask — 1,38 %
- Excite — 0,07 %
- All the Web — 0,02 %
По данным аналитической компании comScore все поисковые сайты в декабре 2007 года обработали 66 млрд 221 млн поисковых запросов.[2][3] Яндекс попал в статистику и находится на 9-ом месте. Таблица сравнения поисковых систем: http://s41.radikal.ru/i091/0906/93/eabbd5e9414e.bmp
Содержание
|
История
Хронология Год Система Событие| 1993 | Aliweb | Запуск |
| 1993 | JumpStation | Запуск |
| 1994 | WebCrawler | Запуск |
| 1994 | AltaVista | Запуск |
| 1995 | Excite | Запуск |
| 1995 | Open Text | Запуск |
| 1995 | Magellan | Запуск |
| 1995 | SAPO | Запуск |
| 1996 | Inktomi | Основана |
| 1996 | HotBot | Основана |
| 1996 | Ask Jeeves | Основана |
| 1996 | Aport | Запуск |
| 1997 | Northern Light | Запуск |
| 1997 | Яндекс | Запуск |
| 1998 | Mail.ru | Запуск |
| 1999 | Teoma | Основана |
| 2000 | Окончательный запуск | |
| 2004 | MSN Search | Запуск (бета) |
| 2005 | бета) | |
| 2006 | Ask.com | Запуск |
| 2006 | Live Search | Запуск |
| 2006 | Gogo.ru | Запуск (бета) |
Одним из первых инструментов поиска в интернете (до WWW) был Archie.
Первой поисковой системой для Всемирной паутины был «Wandex», уже не существующий индекс, который создавал «World Wide Web Wanderer» — бот, разработанный Мэтью Грэем (англ. Matthew Gray) из Массачусетского технологического института в 1993. Также в 1993 году появилась поисковая система «Aliweb», работающая до сих пор. Первой полнотекстовой (т. н. «crawler-based», то есть индексирующей ресурсы при помощи робота) поисковой системой стала «WebCrawler», запущенная в 1994. В отличие от своих предшественников, она позволяла пользователям искать по любым ключевым словам на любой веб-странице — с тех пор это стало стандартом во всех основных поисковых системах. Кроме того, это был первый поисковик, о котором было известно в широких кругах. В 1994 был запущен «
Вскоре появилось множество других конкурирующих поисковых машин, таких как «Excite», «Infoseek», «Inktomi», «Northern Light» и «интернет-каталогами, такими, как «Yahoo!». Позже каталоги соединились или добавили к себе поисковые машины, чтобы увеличить функциональность. В 1996 году русскоязычным пользователям интернета стало доступно морфологическое расширение к поисковой машине Altavista и оригинальные российские поисковые машины Aport. 23 сентября 1997 была открыта поисковая машина Яндекс.
В последнее время завоёвывает всё большую популярность практика применения методов кластерного анализа и метапоиска. Из международных машин такого плана наибольшую известность получила «Clusty» компании Vivísimo. В 2005 году на российских просторах при поддержке МГУ запущен поисковик кластеризацию. В 2006 году открылась российская метамашина [4] с визуальной кластеризацией.
Помимо поисковых машин для Всемирной паутины, существовали и поисковики для других протоколов, такие как Archie для поиска по анонимным Gopher.
Популярные поисковые системы
- Всеязычные:
- [5])
- Yahoo! (0,4 % Рунета) и принадлежащие этой компании поисковые машины:
- Inktomi
- MSN (0,2 % Рунета) (принадлежит компании Англоязычные и международные:
- AskJeeves (механизм Teoma)
- Русскоязычные — большинство «русскоязычных» поисковых систем индексируют и ищут тексты на многих языках — украинском, белорусском, английском и др. Отличаются же они от «всеязычных» систем, индексирующих все документы подряд, тем, что в основном индексируют ресурсы, расположенные в доменных зонах, где доминирует русский язык или другими способами ограничивают своих роботов русскоязычными сайтами.
- Яндекс (44,4 % Рунета)
- Gogo.ru (0,3 % Рунета)
- Aport (0,2 % Рунета)
Примечания
- ↑ http://marketshare.hitslink.com/report.aspx?qprid=4&qptimeframe=M&qpsp=107&qpdt=1&qpct=3&qpf=1
- ↑ http://www.comscore.com/press/release.asp?press=2018
- ↑ http://habrahabr.ru/blog/yandex/34614.html
- ↑ 12.06.2006: Nigma.ru тестирует AJAX-интерфейс для поиска
- ↑ данные об охвате русскоязычных поисковых запросов указаны согласно статистике LiveInternet
См. также
- Список поисковых машин
- Информационный поиск
- Поисковая оптимизация
- Статистика запросов
- Глубокая паутина
- Поисковый спам
- Каталог ресурсов в Интернете
- DataparkSearch
- Wikia Search
- Списки библиотек и поисковые системы
-
Ссылки
- Захаров Н. В. Информационно-поисковые системы в филологических науках
- История поисковых систем
- UFOSETI — поиск НЛО и пришельцев в интернете
- Портал поисковых технологий «Search Tools» (англ.)
Литература
- Ашманов Игорь Станиславович, Иванов Андрей Александрович Продвижение сайта в поисковых системах. — М.: «Вильямс», 2007. — С. 304. — ISBN 978-5-8459-1155-1
- Колисниченко Денис Николаевич Поисковые системы и продвижение сайтов в Интернете. — М.: «Диалектика», 2007. — С. 272. — ISBN 978-5-8459-1269-5
Wikimedia Foundation. 2010.
dic.academic.ru
/ Билеты к экз / 5. Поиск в Интернет. Каталоги. Информационно-поисковые системы. Механизмы поиска в Интернет
-
Поиск в Интернет. Каталоги. Информационно-поисковые системы. Механизмы поиска в Интернет.
ИПС (информационно-поисковая система) – это система, обеспечивающая поиск и отбор необходимых данных в специальной базе с описаниями источников информации (индексе) на основе информационно-поискового языка и соответствующих правил поиска.
Главной задачей любой ИПС является поиск информации релевантной информационным потребностям пользователя. Очень важно в результате проведенного поиска ничего не потерять, то есть найти все документы, относящиеся к запросу, и не найти ничего лишнего. Поэтому вводится качественная характеристика процедуры поиска – релевантность.
Релевантность – это соответствие результатов поиска сформулированному запросу.
Далее мы будем, в основном, рассматривать ИПС для всемирной паутины (WWW). Основными показателями ИПС для WWW являются пространственный масштаб и специализация.
По пространственному масштабу ИПС можно разделить на локальные, глобальные, региональные и специализированные. Локальные поисковые системы могут быть разработаны для быстрого поиска страниц в масштабе отдельного сервера.
Региональные ИПС описывают информационные ресурсы определенного региона, например, русскоязычные страницы в Интернете. Глобальные поисковые системы в отличие от локальных стремятся объять необъятное – по возможности наиболее полно описать ресурсы всего информационного пространства сети Интернет.
Кроме того, ИПС также могут специализироваться по поиску различных источников информации, например, документов WWW, файлов, адресов и т.д.
Рассмотрим подробнее основные задачи, которые должны решить разработчики ИПС. Как следует из определения, ИПС для WWW проводят поиск в собственной базе (индексе) с описанием распределенных источников информации.
Следовательно, сначала нужно описать информационные ресурсы и создать индекс. Построение индекса начинается с определения начального набора URL источников информации. Затем проводится процедура индексирования.
Индексирование – описание источников информации и построение специальной базы данных (индекса) для эффективного поиска.
В некоторых информационно-поисковых системах описание источников информации проводится персоналом ИПС, то есть, людьми, которые составляют краткую аннотацию на каждый ресурс. Затем, как правило, проводится сортировка аннотаций по темам (составление тематического каталога). Конечно, описание, составленное человеком, будет совершенно адекватно источнику. Правда, в этом случае процедура описания занимает значительный период времени, поэтому формируемый индекс имеет, как правило, ограниченный объем. Зато поиск в подобной системе можно будет проводить так же легко, как в тематических каталогах библиотек.
В ИПС второго типа процедура описания информационных ресурсов автоматизирована. Для этого разрабатывается специальная программа-робот, которая по определенной технологии обходит ресурсы, описывает их (проводит индексирование) и анализирует ссылки с текущей страницы для расширения области поиска. Как может описать документ программа? Чаще всего просто составляется список слов, которые встречаются в тексте и других частях документа, при этом учитывается частота повторения и местоположение слова, то есть, слову приписывается своеобразный весовой коэффициент в зависимости от его значимости. Например, если слово находится в названии Web-страницы, робот пометит этот факт для себя. Поскольку описание автоматизировано, затраты времени невелики, и индекс может оказаться очень большим по размеру.
Следовательно, следующей задачей для ИПС второго типа является разработка робота-индексировщика. Для поиска в системах данного типа пользователю придется научиться составлять запросы, в простейшем случае состоящие из нескольких слов. Тогда ИПС будет искать в своем индексе документы, в описаниях которых встречаются слова из запроса. Для проведения более качественного поиска необходимо разрабатывать специальный язык запросов для пользователя. В зависимости от особенностей построения модели индекса и поддерживаемого языка запросов разрабатывается механизм поиска и алгоритм сортировки результатов поиска. Поскольку индекс имеет значительный объем, количество найденных документов может оказаться достаточно большим. Следовательно, чрезвычайно важно, как поисковая машина проведет поиск и отсортирует его результаты.
Не последнее значение имеет внешний вид поисковой системы, предстающий перед пользователем, поэтому одной из задач является разработка удобного и красивого интерфейса. Наконец, исключительно важна форма представления результатов поиска, поскольку пользователю необходимо узнать как можно больше о найденном источнике информации, чтобы принять правильное решение о необходимости его посещения.
Для обращения к поисковому серверу пользователь использует стандартную программу-клиент для всемирной паутины, то есть браузер. По адресу домашней страницы ИПС пользователь работает с интерфейсом поисковой системы, который служит для общения пользователя с поисковым аппаратом системы (системой формирования запросов и просмотра результатов поиска).
Информационно-поисковые системы
Основным компонентом ИПС является поисковая машина, которая служит для перевода запроса пользователя в формальный запрос системы, поиска ссылок на информационные ресурсы и выдачи результатов поиска пользователю.
Как уже говорилось ранее, поиск осуществляется в специальной базе, именуемой индексом. Архитектура индекса устроена таким образом, чтобы поиск проходил максимально быстро, и при этом можно было отследить ценность каждого из найденных ресурсов. Некоторые системы сохраняют запросы пользователя в его личной базе данных, поскольку на отладку каждого запроса уходит много времени, и чрезвычайно важно хранить запросы, на которые получен удовлетворительный ответ.
Робот-индексировшик – программа, которая служит для сканирования Интернет и поддержки базы данных индекса в актуальном состоянии.
Web-сайты – те информационные ресурсы, доступ к которым обеспечивает ИПС.
Как известно, Web-страница – это сложный документ, состоящий из множества элементов. При описании подобного документа программой-роботом необходимо учитывать, в какой именно части Web-страницы встретилось данное слово. Источниками индексирования для документов WWW являются:
-
Заголовки (Title).
-
Заглавия.
-
Аннотация (Description).
-
Списки ключевых слов (KeyWords).
-
Гипертекстовые ссылки.
-
Полные тексты документов.
Кстати, поисковые системы, которые описывают абсолютно весь текст документа WWW, называются полнотекстовыми.
Для того, чтобы описать файл в ресурсе FTP используется URL. Для описания статьи в группе новостей источниками индексирования являются поля Тема (Subject) и Keywords (ключевые слова).
Во время процедуры индексирования часто производится нормализация лексики (приведение слова к базовой форме), некоторые неинформативные слова, например, союзы или предлоги, игнорируются. В каждой ИПС существует свой список называемых стоп-слов, которые игнорируются в процессе индексирования. В системах с сильно изменяемыми языками, например, русским, проводится учет морфологии.
Учет морфологии означает умение работать с различными формами слов конкретного языка.
Здесь следует отметить достаточную сложность русского языка, слова которого изменяются по числам, падежам, родам и временам, причем зачастую неожиданным образом. Например: идет, шел, пойдет, идут и т.д. Все существующие ИПС с учетом морфологии русского языка используют "Грамматический словарь русского языка", составленным Андреем Анатольевичем Зализняком. Словарь включает 90000 словарных статей, по каждому слову даются сведения о том, изменяемо ли оно, и как именно оно склоняется или спрягается.
Из вышеизложенного следует, что основными инструментами поиска информации в WWW являются ИПС.
Однако в Интернет существуют средства поиска, имеющие принципиальные отличия от рассмотренных выше ИПС. В общем случае, можно выделить следующие поисковые инструменты для WWW:
-
поисковые системы,
-
метапоисковые системы и программы ускоренного поиска.
Центральное место по праву принадлежит поисковым системам, которые в свою очередь подразделяются на каталоги, автоматические индексы (поисковые машины) и каталоги-индексы. Только поисковые системы почти в полном объеме обладают возможностями и свойствами ИПС.
Каталог – поисковая система с классифицированным по темам списком аннотаций со ссылками на web-ресурсы. Классификация, как правило, проводится людьми.
Рассмотрим особенности систем-каталогов.
Поиск в каталоге очень удобен и проводится посредством последовательного уточнения тем. Тем не менее, каталоги поддерживают возможность быстрого поиска определенной категории или страницы по ключевым словам с помощью локальной поисковой машины.
База данных ссылок (индекс) каталога обычно имеет ограниченный объем, заполняется вручную персоналом каталога. Некоторые каталоги используют автоматическое обновление индекса.
Результат поиска в каталоге представляется в виде списка, состоящего из краткого описания (аннотации) документов с гипертекстовой ссылкой на первоисточник.
Среди самых популярных зарубежных каталогов можно упомянуть: Yahoo (www.yahoo.com), Magellan (www.mckinley.com),
Российские каталоги: @Rus (www.atrus.ru); Weblist (www.weblist.ru); Созвездие интернет (www.stars.ru).
Поисковая система – система с формируемой роботом базой данных, содержащей информацию об информационных ресурсах.
Отличительной чертой поисковых систем является тот факт, что база данных, содержащая информацию об Web-страницах, статьях Usenet и т.д., формируется программой-роботом. Поиск в такой системе проводится по запросу, составляемому пользователем, состоящему из набора ключевых слов или фразы, заключенной в кавычки. Индекс формируется и поддерживается в актуальном состоянии роботами-индексировщиками.
Зарубежные поисковые машины (системы):
Google - www.google.com (примерно 38% охвата русскоязычных запросов)
Altavista- www.altavista.com
Excite www.excite.com
HotBot - www.hotbot.com
Nothern Light- www.northernlight.com
Go (Infoseek) www.go.com (infoseek.com)
Fast www.alltheweb.com
Российские поисковые машины:
Яndex - www.yandex.ru (или www.ya.ru) (48% охвата русскоязычных запросов)
Рэмблер - www.rambler.ru
Апорт- www.aport.ru
Метапоисковая система – система, не имеющая своего индекса, способная послать запросы пользователя одновременно нескольким поисковым серверам, затем объединить полученные результаты и представить их пользователю в виде документа со ссылками.
6 Принципы работы метапоисковых систем. Механизмы поиска в интернет. Язык запросов.
При работе метапоисковой системы из полученного от поисковых систем множества документов необходимо выделить наиболее релевантные, то есть соответствующие запросу пользователя.
Простейшие метапоисковые системы реализуют стандартный подход, представленный на рис. 1. В таких системах анализ полученных описаний документов не производится, что может поставить нерелевантные документы, идущие первыми в одной поисковой системе, выше релевантных в другой, чем существенно понизить качество самого поиска.
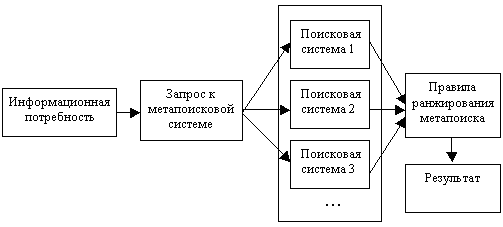
Рис.1 Стандартная метапоисковая система
При разработке следующего поколения метапоисковых систем были учтены недостатки, присущие стандартным метапоисковым системам. Были созданы системы с возможностью выбора тех поисковых машин, в которых, по мнению пользователя, он с большей вероятностью может найти то, что ему нужно (рис. 2)
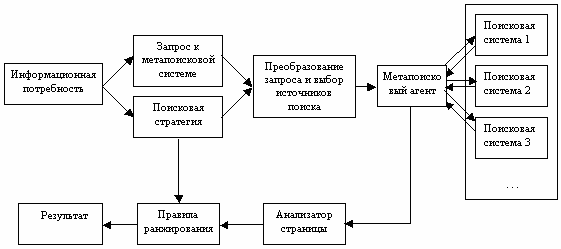
Рис. 2. Следующее поколение метапоисковых систем
Кроме этого, такой подход позволяет уменьшить используемые вычислительные ресурсы метапоискового сервера, не перегружая его слишком большим объемом ненужной информации и серьезно сэкономить трафик. Здесь нужно отметить, что в любой системе метапоиска наиболее узким местом в основном является пропускная способность канала передачи данных, так как обработка страниц с результатами поиска, полученными от нескольких десятков поисковых серверов не является слишком трудоемкой операцией, потому что затраты времени на обработку информации на порядки меньше времени прихода страниц, запрошенных у поисковых серверов.
Как пример систем, имеющих подобную организацию, можно назвать Profusion,Ixquick,SavvySearch,MetaPing.
Примером метапоисковой системы является Nigma(Нигма. РФ) — российская интеллектуальнаяметапоисковаясистема.
Программа ускоренного поиска – это программа с возможностями метапоисковой системы, устанавливаемая на локальном компьютере.
Принципиальным отличием метапоисковых систем и программ ускоренного поиска от ИПС является отсутствие своего собственного индекса. Зато они превосходно умеют использовать результаты работы других поисковых систем.
Механизмы поиска
Обобщенная технология поиска состоит из следующих этапов:
-
Пользователь формулирует запрос
-
Система проводит поиск документов (или их поисковых образов)
-
Пользователь получает результат (сведения о документах)
-
Пользователь совершенствует или реформирует запрос
-
Организация нового поиска...
Как правило, поисковые машины поддерживают два режима: режим простого поиска и режим расширенного поиска. Рассмотрим обобщенные возможности.
Формирования запроса в режиме простого поиска. Можно просто вводить через пробел одно или несколько слов; поиск слов со всевозможными окончаниями моделируется символом * в конце слова. Многие системы позволяют искать словосочетания или фразу, для этого необходимо ее заключить в кавычки. Возможно обязательное включение или исключение определенных слов.
Основная проблема поиска по примитивно составленному запросу (в виде перечисления ключевых слов) заключается в том, что поисковая машина найдет все страницы, на которых указанные слова встречаются в любой части документа. Как правило, количество найденных страниц будет слишком велико.
Для улучшения качества поиска в режиме простого поиска допустимо использование логических операторов и операторов, позволяющих ограничить область поиска, а также выбор определенной категории документов из представленного списка.
Многие поисковые системы включают в свой язык составления запросов специальные операторы, позволяющие проводить поиск в определенных зонах документа, например, в его заголовке, или искать документ по известной части его адреса.
Режим расширенного или детального запроса в разных системах реализован индивидуально, но чаще всего это бланк, в котором упомянутые операторы и ключевые элементы реализуются простой установкой соответствующих флажков или выбором параметров из списка.
Ниже в качестве примера приведены сведения из раздела помощь поисковой системы Yandex: окно расширенного поиска, язык запросов, искать в найденном.
Искать в найденном Если в результате запроса Яндекс нашел много документов, но по более широкой теме, чем вам хочется, вы можете сократить этот список, уточнив запрос. Еще один вариант — включить флажок в найденном в форме поиска, задать дополнительные ключевые слова, и следующий поиск будет вестись только по тем документам, которые были отобраны в предыдущем поиске.
Памятка по использованию языка запросов
|
Пример |
Значение |
|
"К нам на утренний рассол" |
Слова идут подряд в точной форме |
|
"Прибыл * посол" |
Пропущено слово в цитате |
|
полгорбушки & мосол |
Слова в пределах одного предложения |
|
снаряжайся && добудь |
Слова в пределах одного документа |
|
глухаря | куропатку | кого-нибудь |
Поиск любого из слов |
|
не смогешь |
Неранжирующее "и": выражение после оператора не влияет на позицию документа в выдаче |
|
я должон /2 казнить |
Расстояние в пределах двух слов в любую сторону (то есть между заданными словами может встречаться одно слово) |
|
государственное дело && /3 улавливаешь нить |
Расстояние в 3 предложения в любую сторону |
|
нешто я ~~ пойму |
Исключение слова пойму из поиска |
|
при моем /+2 уму |
Расстояние в пределах двух слов в прямом порядке |
|
чай ~ лаптем |
Поиск предложения, где слово чай встречается без слова лаптем |
|
щи /(-1 +2) хлебаю |
Расстояние от одного слова в обратном порядке до двух слов в прямом |
|
!Соображаю !что !чему |
Слова в точной форме с заданным регистром |
|
получается && (+на | !мне) |
Скобки формируют группы в сложных запросах |
|
!!политика |
Словарная форма слова |
|
title:(в стране) |
Поиск по заголовкам документов |
|
url:ptici.narod.ru/ptici/kuropatka.htm |
Поиск по URL |
|
беспременно inurl:vojne |
Поиск с учетом фрагмента URL |
|
host:lib.ru |
Поиск по хосту |
|
rhost:ru.lib.* |
Поиск по хосту в обратной записи |
|
site:http://www.lib.ru/PXESY/FILATOW |
Поиск по всем поддоменам и страницам заданного сайта |
|
mime:pdf |
Поиск по одному типу файлов |
|
lang:en |
Поиск с ограничением по языку |
|
domain:ru |
Поиск с ограничением по домену |
|
date:200712* |
Поиск с ограничением по дате |
|
государственное дело && /3 улавливаешь нить |
Расстояние в 3 предложения в любую сторону |
|
нешто я ~~ пойму |
Исключение слова пойму из поиска |
Интересной возможностью является поиск документов в сети, ссылающиеся на страницу с указанным вами адресом (URL). Таким образом, можно найти в сети страницы, на которых есть ссылки на ваш Web-сайт. Некоторые системы позволят ограничить область поиска внутри указанного домена.
В качестве дополнительных специальных операторов можно выделить:
-
Операторы поиска документов с определенным графическим файлом;
-
Операторы ограничения по дате искомых страниц;
-
Операторы близости между словами;
-
Операторы учета словоформы;
-
Операторы сортировки результатов (по релевантности, свежести, старости).
Следует заметить, что, к великому сожалению, на сегодняшний день не существует стандарта на количество и синтаксис поддерживаемых операторов для различных поисковых систем. Попытки разработать стандарт на синтаксис поддерживаемых операторов предпринимаются, поэтому есть надежда на то, что разработчики поисковых систем позаботятся об удобстве пользователей. На данном этапе развития средств поиска, пользователь, обращаясь к определенной поисковой системе, непременно должен в первую очередь ознакомиться с ее правилами составления запросов. Как правило, на домашней странице будет обязательно присутствовать ссылка Помощь (Help), по которой вы перейдете к справочной информации.
Различные поисковые системы описывают разное количество источников информации в Интернет. Поэтому нельзя ограничиваться поиском только в одной из указанных поисковых системах.
Рассмотрим способы представления результатов поиска в поисковых машинах.
Чаще всего количество найденных документов превышает несколько десятков, а в отдельных случаях может достигать сотен тысяч! Поэтому в качестве формы выдачи составляется список документов по 5-10-15 единиц на странице с возможностью перехода к следующей порции внизу страницы. Обязательно указывается заголовок и URL(адрес) найденного документа, иногда система указывает в процентах степень релевантности документа.
В описании документа чаще всего содержится несколько первых предложений или выдержки из текста документа с выделением ключевых слов. Как правило, указана дата обновления (проверки) документа, его размер в килобайтах, некоторые системы определяют язык документа и его кодировку (для русскоязычных документов).
Что можно делать с полученными результатами? Если название и описание документа соответствует вашим требованиям, можно немедленно перейти к его первоисточнику по ссылке. Это удобнее делать в новом окне, чтобы иметь возможность далее анализировать результаты выдачи. Многие поисковые системы позволяют проводить поиск в найденных документах, причем вы можете уточнить ваш запрос введением дополнительных терминов.
Если интеллектуальность системы высока, вам могут предложить услугу поиска похожих документов. Для этого вы выбираете особо понравившийся документ и указываете его системе в качестве образца для подражания.
Однако, автоматизация определение похожести – весьма нетривиальная задача, и зачастую эта функция работает неадекватно вашим надеждам. Некоторые поисковики позволяют провести пересортировку результатов. Для экономии вашего времени можно сохранить результаты поиска в виде файла на локальном диске для последующего изучения в автономном режиме.
StudFiles.ru
Поисковые системы: состав, функции, принципы работы.
Поисковая система - это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). Наиболее крупные международные поисковые системы: «Google», «Yahoo», «MSN». В русском Интернете это – «Яндекс», «Рамблер», «Апорт».
Опишем основные характеристики поисковых систем:
-
Полнота
Полнота - одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
-
Точность
Точность - еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5). Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
-
Актуальность
Актуальность - не менее важная составляющая поиска, которая характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. Например, на следующий день после появления интересной новости, большое количество пользователей обратились к поисковым системам с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток, однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию у крупных поисковых систем так называемой «быстрой базы», которая обновляется несколько раз в день.
-
Скорость поиска
Скорость поиска тесно связана с его устойчивостью к нагрузкам. Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
-
Наглядность
Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска.одробные пояснения по странице результатов поиска, например у «Яндекса» можно посмотреть по ссылке http://help.yandex.ru/search/?id=481937.
4. Краткая история развития поисковых систем
В начальный период развития Интернет, число его пользователей было невелико, а объем доступной информации сравнительно небольшим. В большинстве своем, доступ к сети Интернет имели лишь сотрудники научно-исследовательской сферы. В это время задача поиска информации в Интернете не была столь актуальной, как в настоящее время.
Одним из первых способов организации доступа к информационным ресурсам сети стало создание открытых каталогов сайтов, ссылки на ресурсы в которых группировались согласно тематике. Первым таким проектом стал сайт Yahoo.com, открывшийся весной 1994 года. После того, как количество сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска нужной информации по каталогу. В полном смысле это еще не было поисковой системой, так как поисковая область была ограничена только ресурсами, присутствующими в каталоге, а не всеми Интернет ресурсами.
Каталоги ссылок широко использовались ранее, однако практически полностью утратили свою популярность в настоящее время. Так как даже современные, огромные по своему объему каталоги, содержат информацию лишь о ничтожно малой части сети Интернет. Самый большой каталог сети DMOZ (его еще называют Open Directory Project) содержит информацию о 5 миллионах ресурсов, тогда как база поисковой системы Google состоит из более чем 8 миллиардов документов.
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в сети Интернет.
В 1997 году Сергей Брин и Ларри Пейдж создали поисковую машину Google в рамках исследовательского проекта в Стэндфордском университете. В настоящий момент Google - самая популярная поисковая система в мире!
В сентябре 1997 года была официально анонсирована поисковая система Yandex, являющаяся самой популярной в русскоязычном Интернете.
В настоящее время существуют три основные международные поисковые системы – Google, Yahoo и MSN, имеющих собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих насчитывается большое количество) использует в том или ином виде результаты трех перечисленных. Например, поиск AOL (search.aol.com) использует базу Google, а AltaVista, Lycos и AllTheWeb – базу Yahoo.
5. Состав и принципы работы поисковой системы
В России основной поисковой системой является «Яндекс», далее - Rambler.ru, Google.ru, Aport.ru, Mail.ru. Причем, на данный момент, Mail.ru использует механизм и базу поиска «Яндекса».
Практически все крупные поисковые системы имеют свою собственную структуру, отличную от других. Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Модуль индексирования
Модуль индексирования состоит из трех вспомогательных программ (роботов):
Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание страницы и извлекает все внутренние ссылки с этой страницы. Скачивается html-код каждой страницы. Для скачивания страниц роботы используют протоколы HTTP. Работает «паук» следующим образом. Робот на сервер передает запрос “get/path/document” и некоторые другие команды HTTP-запроса. В ответ робот получает текстовый поток, содержащий служебную информацию и непосредственно сам документ.
Ссылки извлекаются из тэгов a, area, base, frame, frameset, и др. Наряду со ссылками, многими роботами обрабатываются редиректы (перенаправления). Каждая скачанная страница сохраняется в следующем формате:
-
URL страницы
-
дата, когда страница была скачана
-
http-заголовок ответа сервера
-
тело страницы (html-код)
Crawler («путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача - определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Indexer (робот- индексатор) - программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т.д.
Таким образом, модуль индексирования позволяет обходить по ссылкам заданное множество ресурсов, скачивать встречающиеся страницы, извлекать ссылки на новые страницы из получаемых документов и производить полный анализ этих документов.
База данных
База данных, или индекс поисковой системы - это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
Поисковый сервер
Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска.
Поисковый сервер работает следующим образом:
-
Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (которое и будет впоследствии отображено в виде сниппета, то есть соответствующей запросу текстовой информации на странице выдачи результатов поиска).
-
Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
-
В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск»).
-
Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются.
-
Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов.
Как видно, все эти компоненты тесно связаны друг с другом и работают во взаимодействии, образовывая четкий, достаточно сложный механизм работы поисковой системы, требующий огромных затрат ресурсов.
Ни одна поисковая система не охватывает все ресурсы Интернет.
Каждая поисковая система собирает сведения о ресурсах Интернет, применяя свои уникальные методы, и формирует собственную периодически обновляемую базу данных. Доступ к этой базе предоставляется пользователю.
Поисковые системы реализуют два способа поиска ресурса:
-
Поиск по тематическим каталогам - информация представляется в виде иерархической структуры. На верхнем уровне - общие категории (“Интернет”, “Бизнес”, “Искусство”, “Образование” и т.д.), на следующем уровне категории делятся на разделы и т.д. Самый нижний уровень - ссылки на конкретные веб-страницы или другие информационные ресурсы.
-
Поиск по ключевым словам (индексный поиск или детальный) - пользователь отправляет поисковой системе запрос, состоящий из ключевых слов. Система возвращает пользователю перечень найденных по запросу ресурсов.
Большинство поисковых систем сочетают оба способа поиска.
Поисковые системы могут быть локальными, глобальными, региональными и специализированными.
В русской части Интернет (Рунет) наиболее популярны сейчас поисковые системы общего назначения Rambler (www.rambler.ru), Яндекс (www.yandex.ru), Апорт (www.aport.ru), Гугл (www.google.ru).
Большинство поисковых систем реализовано в виде порталов.
Портал (от англ. portal- главный вход, ворота) -это веб-сайт, который интегрирует различные сервисы Интернет: средства поиска, почту, новости, словари и т.д.
Порталы могут быть специализированными (как, www.museum.ru) и общими (например, www.km.ru).
Поиск по ключевым словам
Набор ключевых слов, по которым ведется поиск, называют также критерием поиска или темой поиска.
Запрос может состоять как из одного слова, так и из сочетания слов, объединенных операторами - символами, по которым система определяет, какое действие ей нужно произвести. Например: запрос “Москва Питер” содержит оператор И (так воспринимается пробел), который указывает, что надо искать документы, в которых есть оба слова - и Москва, и Питер.
Для того, чтобы поиск был релевантным (от англ. relevant -уместный, относящийся к делу), следует учитывать несколько общих правил:
-
Независимо от того, в какой форме употреблено слово в запросе, поиск учитывает все его словоформы по правилам русского языка. Например, по запросу “билет” будут найдены и слова “билетом”, “билету” и т.д.
-
Заглавные буквы следует использовать только в именах собственных, чтобы не просматривать лишние ссылки. По запросу “кузнецов”, например, будут найдены документы, где говорится и о кузнецах, и о Кузнецовых.
-
Желательно сужать круг поиска, используя несколько ключевых слов.
-
Если нужного адреса нет среди первой двадцатки найденных адресов, следует изменить запрос.
-
Если по запросу не найдено ни одной ссылки, прежде чем менять запрос, надо проверить орфографию.
Каждая поисковая система использует свой язык запросов. Для знакомства с ним, пользуйтесь встроенной справкой поисковой системы
Крупные сайты могут иметь встроенные системы поиска информации в пределах своих веб-страниц.
Запросы в подобных системах поиска, как правило, строятся по тем же правилам, что и в глобальных поисковых системах, однако знакомство со справкой и здесь не будет лишним.
Расширенный поиск
Поисковые системы могут предоставлять в распоряжение пользователя механизм, позволяющий формировать сложный запрос. Переход по ссылке Расширенный поиск дает возможность редактировать параметры поиска, указывать дополнительные параметры и выбирать наиболее удобную форму показа результатов поиска. Ниже описаны параметры, которые могут быть заданы при расширенном поиске в системах Япс1ех и Rambler.
|
Описание параметра |
Название в Яндекс |
Название в Rambler |
|
Где искать ключевые слова (заголовок документа, основной текст и т.д.) |
Словарный фильтр |
Поиск по тексту ... |
|
Какие слова должны или не должны присутствовать в документе и насколько точным должно быть совпадение |
Словарный фильтр |
Искать слова запроса... Исключить документы, содержащие следующие слова... |
|
На каком расстоянии друг от друга должны располагаться ключевые слова |
Словарный фильтр |
Расстояние между словами запроса... |
|
Ограничение на дату документа |
Дата |
Дата документа... |
|
Ограничение поиска пределами одного или нескольких сайтов |
Сайт/Вершина |
Искать документы только на следующих сайтах... |
|
Поиск страниц со ссылками на определенный сайт и исключение из поиска страниц со ссылками на определенный сайт |
Ссылка |
|
|
Ограничение поиска по языку документа |
Язык |
Язык документа... |
|
Поиск документов, содержащих картинку с определенным именем или подписью |
Изображение |
|
|
Поиск страниц, содержащих объекты |
Специальные объекты |
|
|
Форма представления результатов поиска |
Формат выдачи |
Вывод результатов поиска |
Некоторые поисковые системы (например, Яндекс) позволяют вводить запросы на естественном языке. Вы пишите, что нужно найти (например: заказ билетов на поезд из Москвы в Питер). Система анализирует запрос и выдает результат. Если он Вас не устраивает, переходите на язык запросов.
StudFiles.ru
Что такое поисковая система
нужно найти ответ на вопрос через поисковую систему
Марат
ПОИСКОВАЯ СИСТЕМА [retrieval system]
Комплекс средств, предназначенный для нахождения и получения (выборки и выдачи) необходимых объектов (в том числе изделий, документов, текстов и т. п. ) , обладающих определенными признаками, соответствующими признакам, указанным в запросах. Различают поисковые системы: "ручные", "механизированные", "автоматизированные" и т. п.
ПОИСКОВАЯ СИСТЕМА (в Интернете) [search(ing) system]
Программно-аппаратный комплекс, предназначенный для производства автоматического поиска информации в Интернете по заданным алгоритмам и критериям. Современные поисковые системы имеют многоуровневую организацию и в своей основе состоят из пяти блоков:
1. Spider - "Паук": производит планомерное обследование Интернета и скачивает адреса всех попавшихся на его пути Web-сайтов, страниц и глобальных ссылок;
2. Crawler, Web-crawler - "Сборщик": перемещается по всем локальным гиперссылкам, найденным на страницах пауком (см. ранее) , скачивает страницы и анализирует их в поисках перекрестных ссылок. Его основные задачи: сканирование Интернет-ресурсов в поисках страниц, содержащих заданную информацию, изменений на страницах и определение дальнейшего пути следования по сети. Аналогичное наименование присваивается программам-роботам, которые строят индексы путем последовательного перехода по гиперссылкам с одной Web-страницы на другую. Они позволяют в автоматическом режиме извлекать различные данные с Web-сайтов, в частности, сведения об их адресах, мета-теги, обычный текст со страниц, размеры страниц, даты последнего обновления, списки ссылок, расположенных на Web-страницах и т. д. По своей сути часто такие программы выполняют функции паука, ползателя, а иногда и индексатора (см. далее) .
Широкое распространение получил также сленговый термин "Ползатель" - вольный перевод англ. crawler: а) тот, кто ползает; б) пресмыкающееся.
p class=li>3. Indexer - "Индексатор": анализирует Web-страницы, скаченные пауком и сборщиком, определяет их тематическую принадлежность, актуальность и популярность у пользователей. Индексатор разбивает страницу на части и анализирует основные ее структурные элементы (заголовки, текст, ссылки и т. п. ) . После анализа индексирует ресурсы ключевыми словами, структурирует их и строит базы данных в виде, удобном для использования и поиска;
4. Database - база данных, являющаяся хранилищем скаченных и обработанных индексатором страниц, снабженная соответствующим поисковым аппаратом, обеспечивающим доступ к содержащимся в ней данным;
5. SE (Search(ing) Engine), Results engine - "Поисковая машина": принимает запросы пользователей, анализирует их, извлекает результаты поиска из БД с использованием ключевых слов и предоставляет пользователю интерфейс для просмотра этих результатов и уточнения поискового предписания.
Наиболее популярными в России крупными поисковыми службами и системами Интернета являются:
[ссылка заблокирована по решению администрации проекта]
www.yandex.ru
www.rambler.ru
www.aport.ru
www.altavista.com
www.yahoo.com
Ys ys
Для мудреца вопрос что то прост. Может не понял я его?
Если поиск нете - всызывайте любой поисковик
http://yandex.ru/
http://www.rambler.ru
или другие
ВВодите ключевіе слова, отражающие суть поиска напр. Женсакая одежда Киев Дарница
и смотрите результаты.
Что не понятно - пишите в кометариях подскажу :)
Читайте также
 1 Структурное и функциональное определения операционной системы
1 Структурное и функциональное определения операционной системы Система целей управления персоналом является основой определения
Система целей управления персоналом является основой определения Нервная система определение
Нервная система определение Акт определение
Акт определение База данных определение
База данных определение Болезнь определение
Болезнь определение Власть определение
Власть определение Генетическое определение пола кратко
Генетическое определение пола кратко Генетические механизмы определения пола
Генетические механизмы определения пола- Выберите один из вариантов определения истины это
 Бетон определение
Бетон определение Вопросы определения
Вопросы определения
 1 Структурное и функциональное определения операционной системы
1 Структурное и функциональное определения операционной системы Система целей управления персоналом является основой определения
Система целей управления персоналом является основой определения Нервная система определение
Нервная система определение Акт определение
Акт определение База данных определение
База данных определение Болезнь определение
Болезнь определение Власть определение
Власть определение Генетическое определение пола кратко
Генетическое определение пола кратко Генетические механизмы определения пола
Генетические механизмы определения пола Бетон определение
Бетон определение Вопросы определения
Вопросы определения